

怎么理解目标跟踪,什么是跟踪?
可以看看今年最新的多目标跟踪综述,相信对你理解有帮助
作者:汽车人 | 原文出处:公众号【自动驾驶之心】加入我们:技术交流群1主要内容
多目标跟踪(MOT)旨在跨视频帧关联目标对象,以获得整个运动轨迹。随着深度神经网络的发展和对智能视频分析需求的增加,MOT在计算机视觉领域的兴趣显著增加。嵌入方法在MOT中的目标位置估计和时间身份关联中起着至关重要的作用,与其他计算机视觉任务(如图像分类、目标检测、重识别和分割)不同,MOT中的嵌入方法有很大的差异,并且从未被系统地分析和总结。本综述首先从七个不同的角度对MOT中的嵌入方法进行了全面概述和深入分析,包括补丁级嵌入、单帧嵌入、跨帧联合嵌入、相关嵌入、顺序嵌入、小轨迹嵌入和跨轨迹关系嵌入。论文进一步总结了现有广泛使用的MOT数据集,并根据其嵌入情况分析了现有最先进方法的优势策略。最后,讨论了一些关键但尚待研究的领域和未来的研究方向。
公众号后台回复【MOTE】获取论文和代码!
公众号后台回复【ECCV2022】获取ECCV2022自动驾驶方向所有论文!
公众号后台回复【领域综述】获取自动驾驶全栈近80篇综述论文!
2领域发展
近年来,多目标跟踪(MOT)得到了广泛的研究,其目的是跨视频帧关联检测到的目标,以获得整个运动轨迹。近年来出现了各种跟踪算法,从图聚类方法[1]、[2]、[3]、[4]到图神经网络[5]、[6]、[7]、[8],这些算法可以跨帧和对象聚合信息;从按检测模式跟踪[9]、[10]、[11]到联合检测和跟踪[5]、[12]、[13]、[14]、[15]、[16],以提高多帧的检测性能;从卡尔曼滤波[17]到递归神经网络(RNN)[18]和长短时记忆(LSTM)[19],以提高与运动线索的关联性能。随着跟踪算法的发展,MOT可以应用于许多任务,例如交通流分析[1]、[20]、[21]、[22]、人类行为预测和姿势估计[23]、[24]、[25]、[26]、自主驾驶辅助[27]、[28],甚至用于水下动物数量估计[29]、[30]、[31]。
MOT系统的流程主要分为嵌入模型和关联算法两部分。在输入多个连续帧的情况下,通过嵌入技术和关联方法估计目标位置和轨迹标识。由于存在光照变化、遮挡、复杂环境、快速摄像机移动、不可靠检测、不同的低图像分辨率,MOT具有挑战性[32]。
此外,跟踪性能可能会受到跟踪算法各个步骤的影响,如检测、特征提取、相关性估计和关联。这些导致显著的变化和不确定性。随着深度神经网络表示学习的最新进展,嵌入方法在MOT中的目标位置估计和时间身份关联中起着至关重要的作用。在这项调查中,我们更关注嵌入学习的回顾,而不是关联,尽管关联在MOT中也很重要。
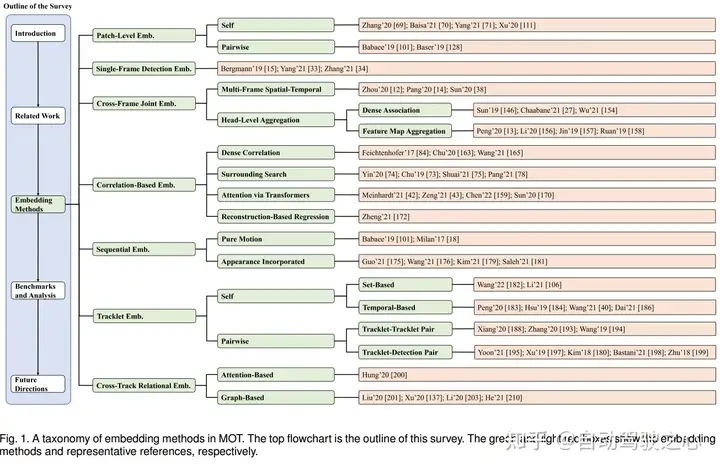
3目标跟踪相关工作
三项任务,即单目标跟踪(SOT)、视频目标检测(VOD)和重新识别(re ID),与MOT高度相关。MOT领域的许多嵌入方法都受到这些任务的启发。本节将对这些任务进行简要回顾。
Single Object Tracking
单目标跟踪(SOT),也称为视觉目标跟踪(VOT),旨在当只有目标的初始状态(在视频帧中)可用时,估计未知的视觉目标轨迹[49]。跟踪目标纯粹由第一帧确定,不依赖于任何类别。受ImageNet大规模视觉识别竞赛(ILSVRC)[55]和视觉对象跟踪(VOT)挑战[56]、[57]中深度学习突破[50]、[51]、[52]、[53]、[54]的启发,嵌入学习方法吸引了视觉跟踪界的极大兴趣,以提供鲁棒的跟踪器。许多作品试图通过学习区分性目标表示来进行跟踪,例如学习干扰感知[58]或目标感知特征[59],利用不同类型的深层特征,如上下文信息[60]、[61]或时间特征/模型[62]、[63],对低级空间特征的全面探索[64]、[65],采用相关引导的注意力模块进行开发。
MOT任务中对象的初始状态未知,需要预定义类别进行跟踪,因此,MOT方法要么采用已定义目标,要么遵循检测跟踪方案[68]、[69]、[70],[71]或利用联合检测和跟踪模型[12]、[15]、[33]、[34]、[37]。
Video Object Detection
视频对象检测(VOD)旨在通过联合识别对象和估计位置来检测多个视频帧中的对象[79]。嵌入方法在视频点播任务中也很重要。嵌入学习可以过滤视频帧的特征,选择相对具有代表性的特征,传播用于检测的关键特征,并在后续帧中描绘值得进行特征过滤的关键区域。
Re-Identification
重识别(Re ID)旨在从不同的图像集合中验证目标身份,通常是从不同的角度、照明和姿势在不同的摄像机中[85]、[86]、[87]。随着深度神经网络的发展和对智能视频监控需求的增加,Re-ID已显著增加了计算机视觉界的兴趣。Re-ID中的特征表示学习已经取得了很大进展。这种嵌入方法包括在没有附加注释提示的情况下为每个图像提取全局特征表示的全局特征学习[88]、聚合部分级局部特征以形成组合表示的局部特征学习[89]、[90]、[91]、使用辅助信息改进特征表示学习的辅助特征学习与属性[92]、[93]、[94]。
4Embedding methods方法汇总
嵌入方法对于目标位置估计和ID关联至关重要。论文将常用的MOT嵌入式方法分为七类,包括补丁级嵌入、单帧嵌入、跨帧联合嵌入、基于相关的嵌入、顺序嵌入、小轨迹嵌入和跨轨迹关系嵌入。对于每一类介绍了有代表性的算法,讨论了它们的优缺点,希望能提供一个更好的解决方案;
1.Patch-Level Box Image Embedding
这一类别中的大多数现有方法侧重于嵌入单个检测[68]、[69]、[70]、[71],而少数方法尝试使用成对嵌入策略直接建模两个检测对象的关系[99]、[100]、[101]。
1. Self-Embedding
一些现有方法将不同帧中的相同对象视为单独的类,并使用交叉熵损失进行ID分类,以学习裁剪检测图像的嵌入,例如[68]、[69]、[70],[72], [102]。一些方法采用triplet loss [71]、[103]、[104]、[105]和基于softmax的对比损失[106]来学习批样本中的区分嵌入,其中来自同一对象的检测被视为正样本,来自不同对象的检测则被视为负样本。
2.Pairwise Embedding
成对嵌入网络不是从单个检测中学习嵌入,而是采用成对检测,直接学习两个检测对象之间的相似性。通常采用二元分类器来指示两个检测是否属于同一目标。
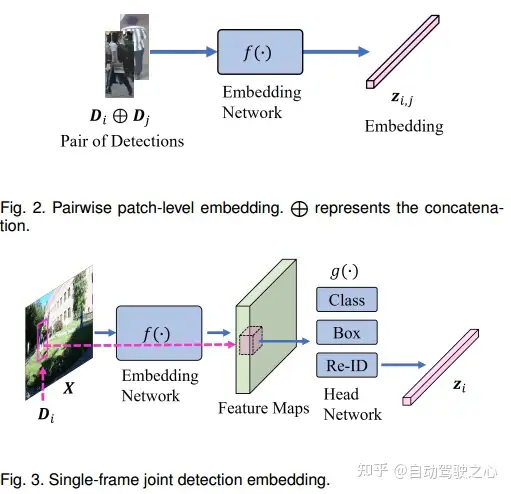
2.Single-Frame Detection Embedding
基于帧的嵌入以端到端的方式联合学习检测和重识别特征。给定输入帧X,网络学习每个检测的鉴别特征;对于基于单帧的Embedding,现有工作通常遵循一些检测模型如faster rcnn、centernet、YOLOv3等,联合学习用于检测和重新识别的嵌入的主要挑战之一来自这两个任务的冲突。检测任务旨在从背景中识别对象类别,如行人和车辆,而Re ID嵌入旨在区分不同的对象而不是类别。一些工作将不同任务的嵌入解耦,以解决多任务学习的问题。
3.Cross-Frame Joint Embedding
为了在多个帧之间联合学习外观和时间特征,跨帧嵌入在MOT中起着重要作用。一些方法[12]、[14]、[38]采用嵌入网络,如3D卷积和卷积LSTM,学习时空特征图进行跟踪,一些方法[13]、[146]、[147]提取单个帧的特征,然后聚集嵌入以建模特定任务头中的时间关系。
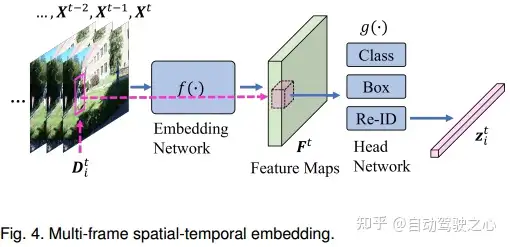
1.多帧时空嵌入
[14]以3D ResNet[54]、[148]为主干生成目标tubes,并在训练中结合了GIOU[149]、focal loss[130]和二进制交叉熵loss。类似地,DMM Net[38]采用3D卷积来学习给定多帧的时空嵌入,以生成tubes,并预测多帧运动、类别和可见性,以生成轨迹。CenterTrack[12]遵循CenterNet框架[133],连接一对连续帧和前一帧的热图,用于联合嵌入、目标中心位置估计以及大小和偏移预测。[39]使用基于shortcut连接的时间先验嵌入的编码器-解码器架构[153]获取多个帧,以同时估计多通道轨迹图,包括存在图、外观图和运动图。由于使用3D神经网络和LSTM学习时间一致性的能力,可以将运动特征合并到嵌入框架中。另一方面,它也增加了训练和测试的计算成本。当前的时空嵌入通常是只考虑几个帧进行联合嵌入,因此,学习到的时间运动特征不足以建模对象的不同运动,学习长期依赖性也需要在未来的工作中作进一步研究。
2.头级特征聚合嵌入
一些工作为密集关联聚合嵌入,DAN[146]提出了一种深度亲和网络,该网络使用以下公式预测一对帧之间检测中心位置的密集关联:从VGG网络的不同层提取的特征[52]。与DAN[146]类似,DEFT[27]设计了一个匹配头,以聚集来自成对框架的嵌入。此外,[27]在匹配头中利用LSTM进行运动预测以进行关联。TraDeS[154]还使用基于 cost volume-based的关联和可变形卷积[155]联合学习基于多帧密集嵌入聚合的偏移、2D、3D和掩码估计。
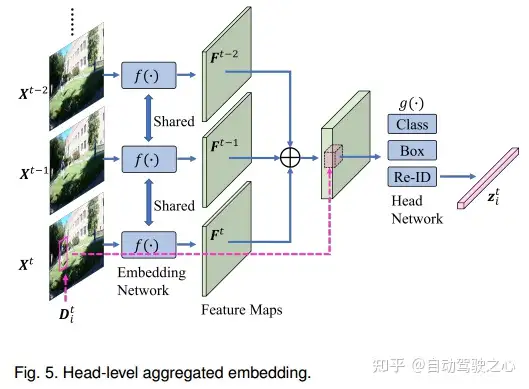
除了聚集密集嵌入之外,一些工作还将一对帧中的特征映射串联起来进行预测。Chainedtracker[13]采用堆叠特征图进行边界框回归和ID验证,使用Faster RCNN框架[129]。[156]将来自相邻帧的特征图连接起来,用于成对2D box回归和基于时空优化的初始3D box估计。[157]通过结合关键点嵌入分支和时间实例嵌入分支来学习时间网,以聚集来自两个帧的特征,用于姿态估计和跟踪。[158]提出了一种端到端姿势引导洞察网络,用于多人姿势跟踪中的数据关联,该网络联合学习特征提取、相似度估计和身份分配。PatchTrack[159]将一对顺序特征映射带到变压器编码器,并使用卡尔曼滤波[160]中先前预测的轨迹作为变压器解码器中的查询。TransCenter[147]还采用Transformer嵌入MOT,其中密集像素级多尺度检测和跟踪查询被前馈到两个基于可变形Transformer编码器和解码器的查询学习网络,以获得检测和跟踪特征。为了学习时间信息,以前的中心热图也在跟踪分支中串联。在嵌入聚合中还利用了其他合适的策略。例如,[5]使用给定一对序列帧的GraphConv[161],基于图神经网络(GNN)聚合节点嵌入。[162]基于从检测到的对象和跟踪的目标中提出的融合追踪,利用从输入帧估计的光流引导,生成融合目标。与多帧时空嵌入相比,基于head-level的聚合嵌入方法使用共享主干单独编码每个帧,大大降低了计算成本。然而,它可能缺乏用于检测和关联的帧之间的低水平像素相关特征。
4.基于相关性的Embedding
受SOT方法的启发,可以通过检测和生成的特征图之间的相关性来优化目标位置。
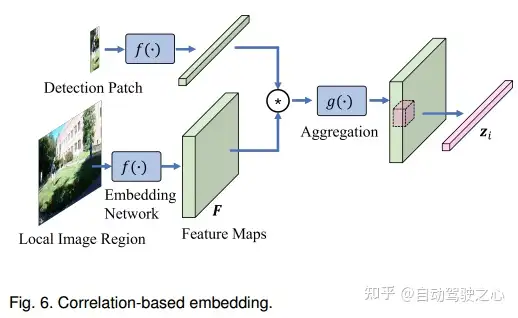
Dense correlation
一些工作估计密集相关特征图。例如,[84]使用相关层,该层学习给定顺序特征映射的密集时间关系。DASOT[163]将数据关联和SOT集成在一个统一的框架中。此外,[165]利用密集特征图估计时间相关性和多尺度空间相关性。
Surrounding search
一些工作通过SOT算法在单个检测和周围局部区域之间进行相关性。具体而言,遵循深度跟踪器SiamFC[166],[74]使用siamese network计算anchor样本与正局部区域和负局部区域之间的相关性。该网络建立在轻量级AlexNet[50]的基础上,采用 triplet loss进行区分学习以生成嵌入。
在 Siamese-RPN跟踪器[167]之后,[72]搜索下一帧中的局部区域,并在短期线索中对前一帧的每次检测进行相关。类似地,在[73]中,对于中心帧中的每个对象,在锚定特征和相邻帧中的局部区域之间进行互相关。SiamMOT[75]提出了显式运动模型(EMM),以估计检测到的面片和下一帧的局部区域之间的交叉信道相关性,采用Faster R-CNN检测器。
Attention via Transformers
随着视觉transformer的发展,一些方法[42]、[43]、[159]、[170]在MOT中采用了transformer,因为transformer使用pairwise attention,可以在嵌入中融合全局信息并提高跟踪性能。查询键机制在跟踪中起着相关性的作用,可以通过测量特征图和轨迹查询之间的相关性的多头注意力[171]获得预测。TransTrack[170]使用Transformer解码器中的轨迹查询和对象查询进行轨迹预测和对象检测。类似地,[42]、[43]还使用Transformer解码器来估计先前轨迹和当前特征图之间的相关性,以进行预测。PatchTrack[159]将来自卡尔曼滤波的预测轨迹作为Transformer解码器中的查询,以估计预测轨迹和来自编码器的特征图之间的相关性。
Sequential Embedding
在MOT中建模时间信息的另一种常用策略是使用递归神经网络进行序列建模,这种序列嵌入方法学习从先前嵌入到当前嵌入的变换动态更新。
一些工作使用Sequential 嵌入来建模运动特征,[101]使用RNN进行运动预测,TrajE[173]采用RNN来估计模拟目标轨迹的高斯混合,[27]、[174]使用LSTM嵌入运动信息,[18] 采用LSTM进行嵌入和关联。一些工作还考虑了Sequential 嵌入中的外观特征。例如,[175]采用卷积选通递归单元(ConvGRU)来聚集外观特征,[176]提出了循环跟踪单元(RTU)来建模长期时间信息,其中RTU将旧外观特征模板、当前节点的外观特征、旧隐藏状态和当前节点的状态特征作为嵌入输入。
5.Cross-Track Relational Embedding
交叉轨迹关系Embedding旨在基于与相邻轨迹的交互来学习对象特征。
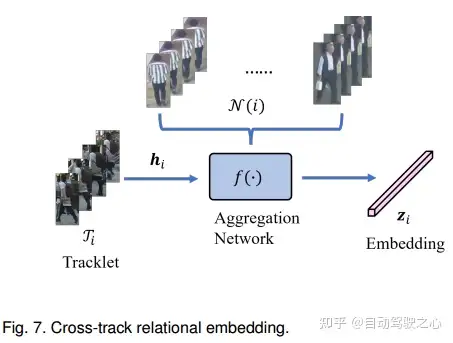
基于attention方法
[175]提出了用于特征提取的时间感知目标注意力和干扰物注意力。基于transformer的跟踪器也使用注意力来获得交叉轨道嵌入,[42]、[43]通过多头注意,使用与其他轨迹和对象的相关性对轨迹嵌入进行编码。TransMOT[41]提出了一种时空图变换transformer来对小轨迹进行编码,并使用空间图解码器来估计小轨迹与检测之间的关联。
基于Graph方法
基于图的方法也广泛用于cross-track embedding。[201]为每个检测到的对象及其k近邻定义局部图,每两帧使用图相似模型(GSM)并通过二元分类来测量关联性。[202]使用GCN学习关联的两个帧中检测的交互特征。DeepMOT[137]提出了一种深度匈牙利网络,该网络使用双向RNN对关联进行建模,并定义了可微网络。[203]分别对运动图网络和外观图网络进行建模。
5Benchmarks和分析
数据集
论文首先回顾了11个广泛使用的MOT数据集,包括KITTI[177]、[211]、[212]、MOT15[213]、DukeMTMCT[117]、MOT16-17[143]、PathTrack[124]、UA-DETRAC[214]、PoseTrack[215]、[216]、MOTS[37]、CityFlow[20]和KITTI MOTS[37]、MOT20[32]、[144]、nuScenes[217]、Waymo[218]、BDD100K[219]、[220]和VisDrone[221]、[222]、[223]、〔224]。
这些数据集主要关注人和车辆跟踪,一些用于一般行人跟踪,一些用于交通流分析和自动驾驶。标注包括二维和三维边界框、姿势和关键点以及实例mask,这些数据集的统计数据汇总如下表所示:
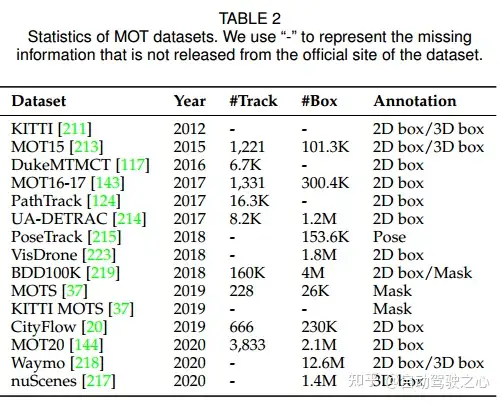
还有其他特定任务的跟踪数据集,如HiEve[225]、[226]、DanceTrack[227]、Omni-MOT[38]、[228]、Virtual KITTI[229]、Apollo-MOTS[111]、TAO-person[230]、WildTrack[231]和GMOT-40[232],这些数据集的详细信息可在参考文献中找到。近年来,可以从数据集收集的角度进行一些观察: 1) 更具挑战性,面向具有高对象密度的拥挤场景; 2) 更多样化的注释格式,2D和3D框用于mask和姿势; 3) 大规模,更多注释或更多轨迹和视频;
评价指标
为了评估MOT的性能,CLEAR MOT[233]、基于ID的度量[117]和HOTA[234]被广泛使用。CLEAR MOT[233]测量检测框和真值框之间的多目标跟踪精度(MOTA)和多目标跟踪精确度(MOPT),提出的MOTA和MOTP基于匹配对、未命中、误报和失配。然而,MOTA过分强调检测性能而不是关联性。基于ID的度量[117]计算结果匹配的真值,该匹配通过跟踪器正确识别目标的时间来衡量跟踪性能。具体而言,二分匹配通过在所有可用的真实和计算数据上最小化失配帧的数量,将一条地面真实轨迹与精确的一条计算轨迹相关联。精确性、召回率和F1分数等标准衡量标准是建立在这种结果匹配的真相之上的,即IDP、IDR和IDF1。然而,IDF1过分强调关联性能而不是检测。[234]中提出了一种更高阶度量,即更高阶跟踪精度(HOTA),用于评估MOT性能。HOTA明确地将执行精确检测、关联和定位的效果平衡到单个统一度量中,用于比较跟踪器。HOTA分解为一系列子度量,能够分别评估五种基本错误类型(检测召回、检测精度、关联召回、关联精度和定位精度)中的每一种,从而能够清晰地分析跟踪性能。
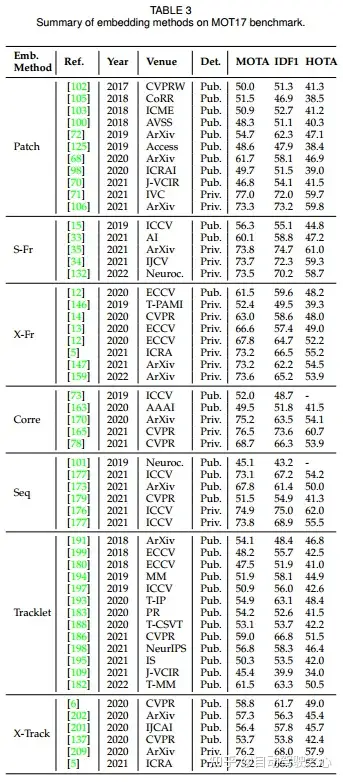
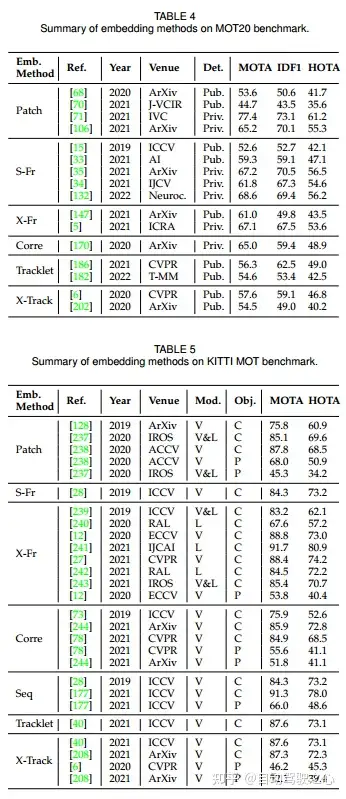
SOTA跟踪方法汇总
6MOD未来方向讨论
针对MOT嵌入方法中一些没有充分研究的领域,本文从非完全监督学习、泛化和域自适应、拥挤场景嵌入、多视图协作和多模态MOT五个方面探讨了MOT嵌入方法的发展趋势和潜在发展方向。
面向未来的MOT嵌入学习,作者总结了有元学习、辅助任务学习、大规模预训练等其它未来的方向。
7参考文献
[1] Recent Advances in Embedding Methods for Multi-Object Tracking: A Survey
自动驾驶之心技术交流群:
自动驾驶之心技术交流群:检测/分割/车道线/跟踪/3D感知/多传感器融合/定位/规划控制等方向!,我们建立了全系列的技术交流群欢迎一起侃侃,也可直接添加博主微信:wenyirumo,备注学校/公司+研究方向+姓名!
干货整理
自动驾驶数据集下载!检测/分割/车道线/交标/车牌/行人识别等
目标检测综述!通用目标检测、数据增强、自动驾驶检测任务、anchor-based、anchor-free方案汇总
语义/实例/全景分割综述!图像分割、视频分割、弱监督无监督分割、点云分割方案汇总
多模态融合综述!Lidar/Radar/Camera数据融合方案汇总
3D检测综述汇总!单目/双目/点云/多模态数据融合检测方案汇总
关键点检测综述!人体2D+3D关键点检测方案汇总
视觉Treansformer综述!视觉transformer和高效transformer方案汇总
多传感器融合综述!多模态/多结果数据融合方案汇总
往期回顾
自动驾驶之心 | 玩转水平集 | 弱监督实例分割新SOTA!(ECCV2022)
自动驾驶之心 | 最新BEV感知基线 | 你确定需要激光雷达?(卡内基梅隆大学)
自动驾驶之心 | 2022最新综述!一文详解自动驾驶中的多模态融合感知算法(数据级/特征级/目标级)
自动驾驶之心 | 2022最新小目标检测综述 | 面向大规模场景的小目标检测:综述和 benchmark
自动驾驶之心 | 计算机视觉2D/3D标注工具汇总!(2D检测/分割/关键点/3D检测/点云)
自动驾驶之心 | 登顶KITTI!Mix-Teaching:适用于单目3D目标检测的半监督方法【清华大学】
自动驾驶之心 | GANet:基于关键点的全局关联车道线检测网络【CVPR2022】
自动驾驶之心 | Wilddash2 —最新自动驾驶全景分割数据集【CVPR2022】
自动驾驶之心 | 2DPASS:2D先验辅助的激光雷达点云语义分割!【ECCV2022】
自动驾驶之心 | 2022最新 | 室外单目深度估计研究综述
自动驾驶之心 | AutoAlignV2:多模态3D目标检测新SOTA!【ECCV2022】
本站所有文章、数据、图片均来自互联网,一切版权均归源网站或源作者所有。
如果侵犯了你的权益请来信告知我们删除。邮箱:dacesmiling@qq.com
下一篇:如何理解目标识别和跟踪?




