

学术速递4|谷歌混合精度量化 | 清华语音人脸视频生成 | 谭铁牛步态识别对抗攻击 | 北大点云数据
几篇本周的paper:
清华:音频驱动的具有自然头部姿势的语音人脸视频生成谭铁牛:对步态识别的时间稀疏对抗性攻击Google Brain:无需专用硬件加速的混合精度量化北大:SemanticPOSS-具有大量动态实例的点云数据集1. 清华:音频驱动的具有自然头部姿势的语音人脸视频生成
类似于AI虚拟主播,根据声音生成视频,嘴型和头的姿态越来越自然……Fake News批量化生产指日可待【狗头】,先看一段图像生成人脸视频的Demo,不是本文的Demo,和本文的语音人脸视频生成还不太一样,主要是了解一下类似的文章:
标题:Audio-driven Talking Face Video Generation with Natural Head Pose
机构:清华、中科大、浙大
作者:Ran Yi, Zipeng Ye, Juyong Zhang, Hujun Bao, Yong-Jin Liu
链接:https://arxiv.org/pdf/2002.10137.pdf摘要:现实世界中说话的人脸通常伴随着自然的头部运动。然而,现有的语音人脸视频生成方法大多只考虑固定头部姿势的人脸动画。针对这一问题,我们提出了一种深度神经网络模型,该模型以源人物的音频信号A和目标人物的极短视频V作为输入,输出具有自然头部姿势(利用V中的视觉信息)、表情和嘴唇同步(同时考虑A和V)的合成的高质量语音人脸视频。在我们的工作中最具挑战性的问题是,自然姿势经常会引起平面内和平面外的头部旋转,这使得合成的有声人脸视频与真实感相去甚远。为了解决这一挑战,我们重建了3D人脸动画,并将其重新渲染为合成帧。为了将这些帧微调成具有平滑背景过渡的逼真帧,我们提出了一种新颖的记忆增强型GaN模块。大量的实验和研究表明,我们的方法可以生成高质量的(即自然的头部动作、表情和良好的嘴唇同步)个性化的说话人脸视频,性能优于最先进的方法。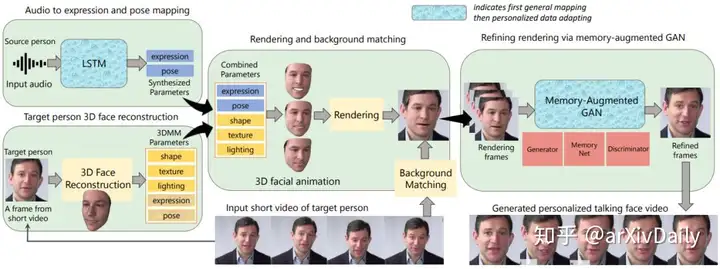


2. 谭铁牛等:对步态识别的时间稀疏对抗性攻击
大幅度降低步态识别准确率的方法,很有用啊,以后出门带上口罩,带上这个,再穿上个目标检测对抗性T恤,防止被识别。。。。【可怕
标题:Temporal Sparse Adversarial Attack on Gait Recognition
机构:中科院自动化所
作者:Ziwen He, Wei Wang, Jing Dong, Tieniu Tan
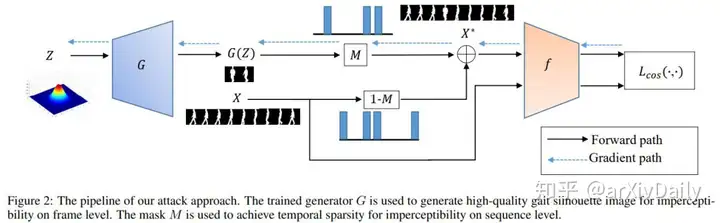
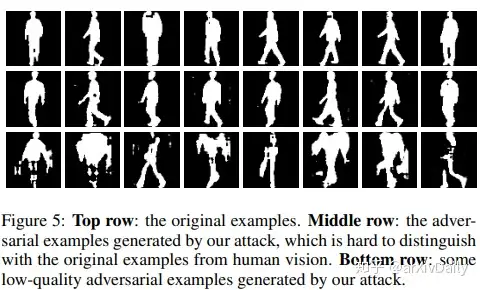
链接:https://arxiv.org/abs/2002.09674摘要:步态识别由于其在远距离身份识别方面的优势,在社会治安领域有着广泛的应用。尽管步态识别系统具有很高的精确度,但它们的对抗健壮性还没有被研究过。在本文中,我们证明了最新的步态识别模型容易受到对手的攻击。在一种新定义的失真度量下,提出了一种新的时间稀疏敌意攻击。采用基于GAN的体系结构从语义上生成对抗性的高质量步态轮廓。通过稀疏地替换或插入少量对抗性步态轮廓,我们提出的方法可以获得较高的攻击成功率。对抗性例子的隐蔽性和攻击成功率得到了很好的平衡。实验结果表明,即使只有1/40帧被攻击,攻击成功率仍达到76.8%。
3. Google Brain:无需专用硬件加速的混合精度量化
“本文的意思嘛,不需要专门硬件的物理混合精度实现,却能产生“混合精度的效果”。不过“Mixed Precision without Mixed Precision”这个名字取的啊,不如来一篇“Spend Money without Money”。。。
标题: Post-training Quantization with Multiple Points: Mixed Precision without Mixed Precision
机构:UT Austin and Google Brain
作者:Xingchao Liu, Mao Ye, Dengyong Zhou, Qiang Liu
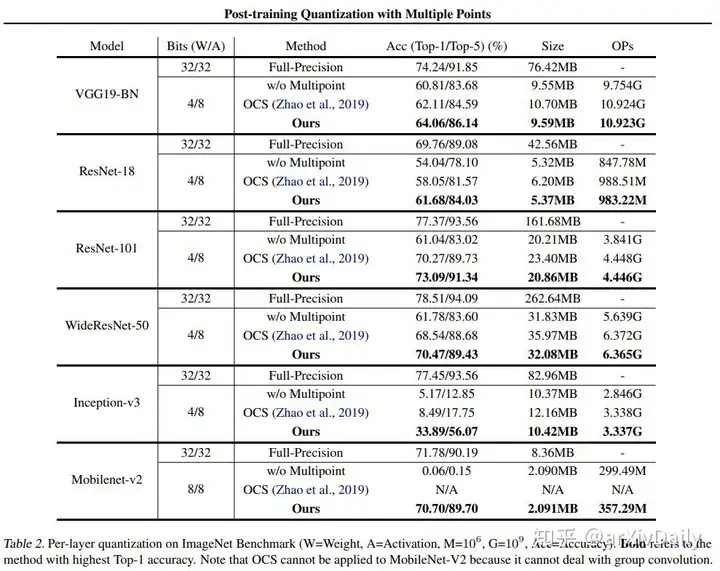
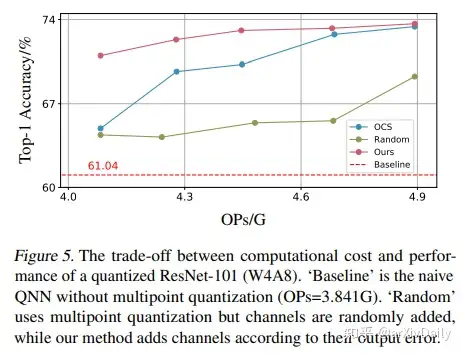
链接:https://arxiv.org/abs/2002.09049本文主要考虑训练后的量化问题,该问题将预训练的深度神经网络的权值离散化,而不需要重新训练模型。本文提出了 Multiple Points量化,这是一种使用低比特数的多个矢量的线性组合来近似全精度权重矢量的量化方法;这与使用单个低精度数字来近似每个权重的典型量化方法不同。在计算上,采用高效的贪婪选择过程来构造多点量化,并根据输出误差,自适应地确定每个量化权向量上的低精度点数。这使得能够为对输出有很大影响的重要权重实现更高的精度水平,从而产生“混合精度的效果”,但不需要物理混合精度实现(这需要专门的硬件加速器)。经验上讲,本文方法可由普通操作数实现,几乎没有内存和计算开销。本文的方法在ImageNet分类上的性能优于一系列最先进的方法,并且可以推广到更具挑战性的任务,如Pascal VOC目标检测。
4. 北大:SemanticPOSS-具有大量动态实例的点云数据集
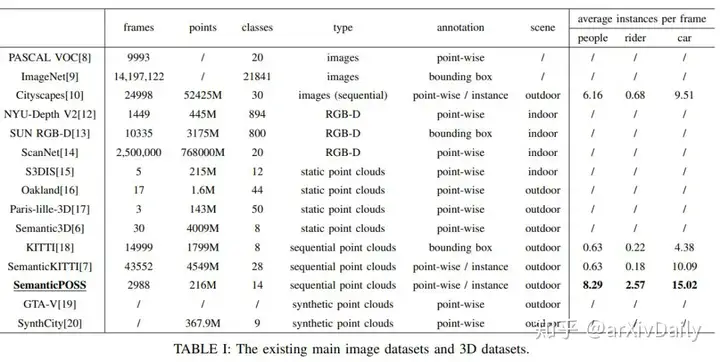
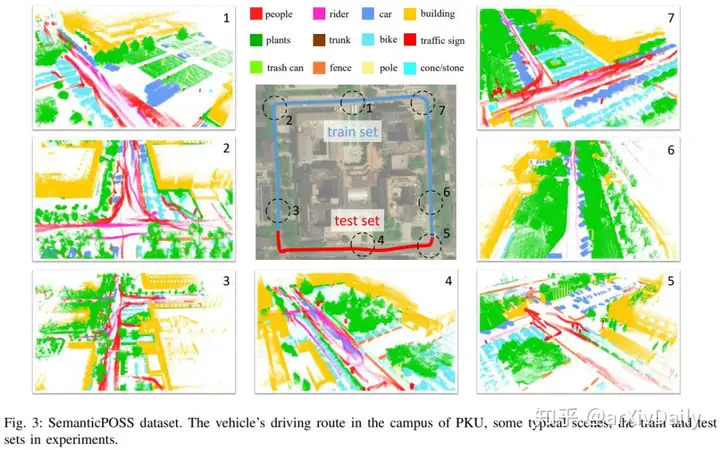
三维语义分割是自动驾驶系统的关键任务之一,下载地址 http://www.poss.pku.edu.cn/
。
标题:SemanticPOSS: A Point Cloud Dataset with Large Quantity of Dynamic Instances
作者:Yancheng Pan, Biao Gao, Jilin Mei, Sibo Geng, Chengkun Li, Huijing Zhao
链接:https://arxiv.org/pdf/2002.09147.pdf近年来,针对三维语义分割任务的深度学习模型得到了广泛的研究,但它们通常需要大量的训练数据。然而,目前用于三维语义分割的数据集存在point-wise标注少、场景多样少、对象动态的少的缺点。本文提出了SemanticPOSS数据集,其中包含2988个具有大量动态实例的各种复杂的LiDAR扫描。这些数据是在北京大学收集的,使用与SemantiKITTI相同的数据格式。此外,我们在SemanticPOSS数据集上对几种典型的3D语义分割模型进行了评估。实验结果表明,SemanticPOSS能够在一定程度上提高人、车等动态对象的预测精度。

往 期 推 荐






本站所有文章、数据、图片均来自互联网,一切版权均归源网站或源作者所有。
如果侵犯了你的权益请来信告知我们删除。邮箱:dacesmiling@qq.com



