联邦学习介绍
联邦学习是一种新的机器学习范式,实现数据安全和隐私保护,近年来,国内外研究学者对其进行研究,本文整理联邦学习相关内容,将系统性的介绍联邦学习。
联邦学习(FL)是一种机器学习设置,许多客户(如移动设备或整个或组织)在中央服务器(如服务提供商)的协调下协作训练一个模型,同时保持训练数据的分散。它体现了集中收集和数据最小化的原则,可以减轻许多由传统的集中机器学习产生的系统性隐私风险和成本。近年来,无论是从研究角度还是应用角度,这一领域都受到了极大的关注。本文描述了联邦学习集的定义特征和挑战,强调了重要的实践约束和考虑因素,然后列举了一系列有价值的研究方向。这项工作的目标是突出具有重要理论和实践意义的研究问题,并鼓励对可能有重大现实影响的问题进行研究。
2016年,McMahan等人[337]提出了联邦学习这个术语,因为学习任务是由参与设备(我们称之为客户端)松散联合解决的,这些设备由中央服务器协调。”在有限的通信带宽下,在大量不可靠的设备上进行不平衡的非iid(相同且独立分布)数据分区,这是一大挑战。
重要的相关工作先于联邦学习这个术语的引入。许多研究团体(包括密码学、数据库和机器学习)追求的一个长期目标是分析和学习分布在许多所有者之间的数据,而不暴露这些数据。对加密数据进行计算的加密方法始于20世纪80年代初[396,492],而Agrawal和Srikant[11]和Vaidya等人[457]是在保护隐私的同时,利用中央服务器学习本地数据的早期例子。相反,即使引入了联邦学习这个术语,我们也没有发现任何一项工作可以直接解决外语学习的全部挑战。因此,术语联邦学习为一组特征、约束和挑战提供了方便的简写,这些特征、约束和挑战经常出现在分散数据上的应用ML问题中,其中隐私是最重要的。
本文来源于2019年6月17 - 18日在谷歌西雅图办公室举行的联邦学习与分析研讨会。在为期两天的活动中,我们清楚地认识到,需要撰写一篇广泛的论文来调查联邦学习领域的许多公开挑战。
讨论的许多问题的一个关键特性是它们本质上是跨学科的——解决它们可能不仅需要机器学习,还需要来自分布式优化、密码学、安全、差分隐私、公平、压缩感知、系统、信息论、统计学等方面的技术。许多最困难的问题都在这些领域的交叉点上,因此我们相信,合作对持续取得进展至关重要。这项工作的目标之一是突出这些领域的技术可能结合的方式,提出了有趣的可能性和新的挑战。
自从联邦学习一词最初被引入并强调移动和边缘设备应用以来[337,334],人们对将FL应用于其他应用的兴趣大大增加,包括一些可能只涉及少量相对可靠的客户端的应用,例如多个组织协作训练一个模型。我们将这两种联合学习设置分别称为“跨设备”和“跨域”。鉴于这些差异,我们提出了一个更广泛的联邦学习的定义:
联邦学习是一种机器学习模式,在中央服务器或服务提供商的协调下,多个实体(客户端)协作解决机器学习问题。每个客户端的原始数据存储在本地,不进行交换或传输;反而,用于及时聚合的集中更新用来实现学习目标。虽然保护隐私的数据分析已经研究了50多年,但直到过去10年才大规模地广泛部署解决方案(例如[177,154])。跨设备联合学习和联合数据分析现在被应用在消费数字产品中。谷歌在Gboard移动键盘[376,22,491,112,383]以及Pixel手机[14]和Android Messages[439]中广泛使用了联邦学习。虽然谷歌开创了跨设备FL,对这个设置的兴趣现在更广泛,例如:苹果正在iOS 13[25]中使用跨设备FL,用于QuickType键盘和“Hey Siri”[26]的语音分类器等应用程序;医生。人工智能正在跨设备发展FL用于医学研究[149],Snips已经探索了用于热词检测的跨设备FL[298]。
跨领域应用也被提出或描述,包括再保险金融风险预测[476]、药品发现[179]、电子健康记录挖掘[184]、医疗数据分割[15,139]和智能制造[354]。
随着对联邦学习技术需求的不断增长,出现了许多工具和框架。其中包括TensorFlow Federated [38], Federated AI Technology Enabler [33],PySyft [399], Leaf [35], PaddleFL[36]和Clara Training Framework [125]详见附录A。包括联邦学习在内的商业数据平台正在成熟的科技公司和规模较小的初创公司开发中。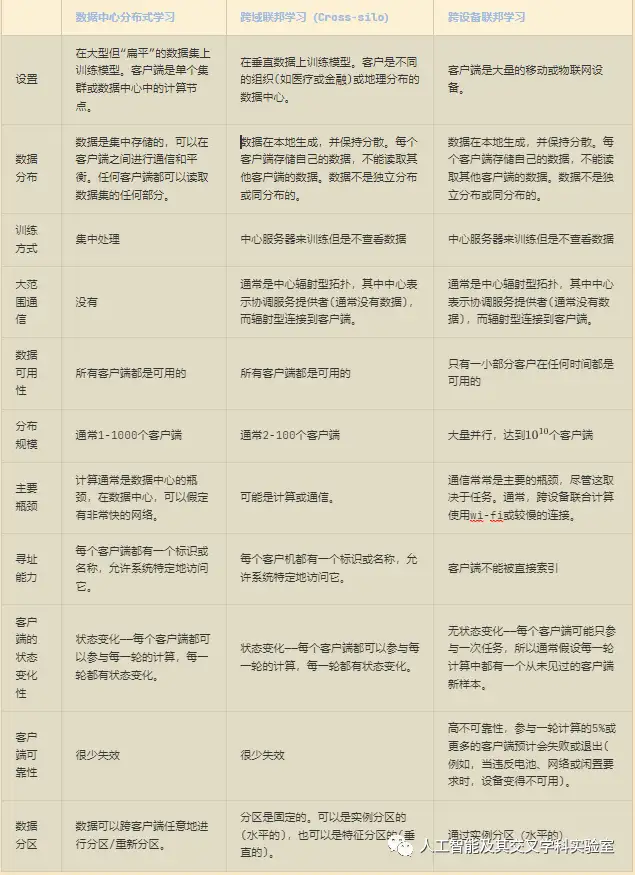
表 联邦学习与传统的机器学习对比
表1对比了跨设备和跨域的联邦学习与跨一系列轴的传统单数据中心分布式学习。这些特征建立了许多实际联邦学习系统通常必须满足的约束条件,因此可以激励和通知联邦学习中的开放挑战。它们将在以下各节中详细讨论。
1.1 跨设备联合学习设置
本节采用应用透视图,与前一节不同的是,本节会给出定义。相反,我们的目标是描述跨设备FL中的一些实际问题,以及它们如何适合更广泛的机器学习开发和部署生态系统。希望为接下来的开放问题提供有用的背景和动机,并帮助研究人员估计在现实系统中部署一种特定的新方法将是多么直接。在考虑FL训练过程之前,我们先画一个模型的生命周期草图。
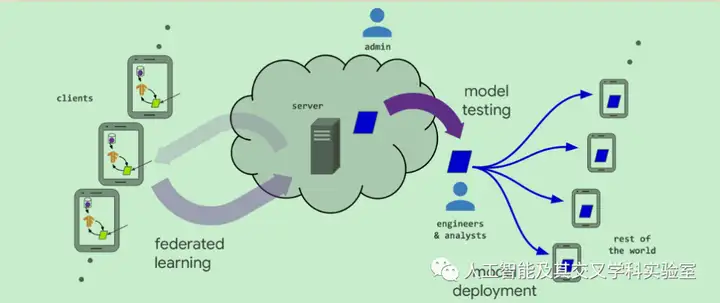
图 联邦学习训练模型的生命周期和联邦学习系统中的各种参与者。之后将从威胁模型的角度重新讨论这个图。
1.1.1 联邦学习模型的生命周期
联邦学习过程通常由模型工程师为特定应用开发模型来驱动。例如,自然语言处理领域的专家可以开发用于虚拟键盘的下一个单词预测模型。图1显示了主要组件和参与者。在高层次上,典型的工作流是:
问题识别:确定联邦学习问题客户端工具:如果需要,客户端(例如在手机上运行的应用程序)将在本地存储必要的训练数据(有时间和数量的限制)。在很多情况下,应用程序已经存储了这些数据(例如,短信应用程序必须存储文本消息,照片管理应用程序已经存储照片)。然而,在某些情况下,可能需要维护额外的数据或元数据,例如,用户交互数据为监督学习任务提供标签。虚拟样机仿真:模型工程师可以在FL模拟中使用代理数据集原型模型架构和测试学习超参数。联邦模型训练:多个联邦训练任务开始训练模型的不同变体,或使用不同的优化超参数。联邦模型评估:在任务经过充分的训练之后(通常是几天,见下文),分析模型并选择好的候选者。分析可以包括在数据中心的标准数据集上计算的度量,或者将模型推到等待客户端的联邦评估,以便对本地客户端数据进行评估。部署:最后,一旦一个好的模型被选中,它会经过一个标准的模型发布过程,包括手动质量保证、实时A/B测试(通常是在一些设备上使用新模型,在其他设备上使用上一代模型,比较它们的性能),模型的特定启动过程由应用程序的所有者设置,通常独立于模型的训练方式。换句话说,这一步同样适用于使用联邦学习或传统数据中心方法训练的模型。联邦学习系统面临的一个主要的实际挑战是使上述工作流程尽可能直接,理想地接近ML系统实现的集中训练的易用性。虽然本文主要关注联邦训练,但还有许多其他组件——包括联邦分析任务,如模型评估和调试。
1.1.2 典型的联邦训练过程
我们现在考虑一个包含McMahan等人[337]和其他许多人的联邦平均算法的FL训练模板;同样,联邦学习的过程有可能变化,但是有很多共同点。
服务器(服务提供商)通过重复以下步骤来编排训练过程,直到停止训练(由监控训练过程的模型工程师决定):
客户端选择:服务器示例来自一组满足资格要求的客户机。例如,为了避免影响设备的用户,移动电话可能只有在插入、未测量的wifi连接且空闲的情况下才会向服务器检入。广播:被选中的客户端从服务器下载当前的模型权重和训练方案。客户端计算:每个选定的设备通过执行训练程序在本地计算对模型的更新,例如,可以在本地数据上运行SGD(如Federated average)。聚合:服务器收集设备更新的聚合。为了提高效率,当有足够多的设备报告结果时,可能会在此时丢弃掉队的设备。这一阶段也是后面将讨论的许多其他技术的集成点,可能包括:用于增加隐私的安全聚合,用于通信效率的有损压缩聚合,以及用于差分隐私的噪声添加和更新裁剪。模型更新:服务器根据参与当前回合的客户端计算出的聚合更新在本地更新共享模型。客户端计算、聚合和模型更新阶段的分离并不是联邦学习的严格要求,它确实排除了某些类的算法,例如异步算法SGD中,每个客户机的更新在其他客户机的更新聚合之前立即应用到模型。这种异步方法可以简化系统设计的某些方面,而且从优化的角度来看也是有益的(尽管这一点还有待讨论)。然而,上述方法在提供不同研究线之间的关注点分离方面具有实质性的优势:压缩、差分隐私和安全多方计算方面的进展可以针对标准原语(如在分散更新上计算总和或平均值)进行开发,然后使用任意优化或分析算法进行组合,只要这些算法以聚合表示。
同样值得强调的是,在两个方面,FL训练过程不应该影响用户体验。首先,如上所述,尽管模型参数通常会在每一轮联合训练的广播阶段发送到一些设备,但这些模型只是训练过程中短暂的一部分,并不用于向用户显示“实时”预测。这很重要,因为训练ML模型具有挑战性,超参数的错误配置可能会产生一个做出糟糕预测的模型。相反,用户可见的模型使用被推迟到模型生命周期的步骤6中详细描述的推出过程。其次,训练本身对用户是不可见的——正如在客户端选择中描述的那样,训练不会减慢设备的速度或耗尽电池,因为它只在设备空闲并连接电源时执行。然而,这些限制带来的有限可用性直接导致了后续将讨论的开放研究挑战,如半循环数据可用性和客户选择中的潜在偏见。
文中引用文献在之后章节中提供。
本站所有文章、数据、图片均来自互联网,一切版权均归源网站或源作者所有。
如果侵犯了你的权益请来信告知我们删除。邮箱:dacesmiling@qq.com
上一篇:FedEx联邦快递介绍
下一篇:邦联和联邦有什么区别?