大约三个月前内地开播了新版倚天屠龙记,并霸占了微博热搜一段时间,而我忍不住就又看了一边旧版的一天屠龙记!哈哈哈哈哈哈。。。结合自己最近所学知识就想对金庸老爷子的这篇小说进行一些小小的人物分析。(本次分析主要是为了学习如何用R语言进行文本数据分析,以及ggplot包的使用)。
1. 人物角色的出场次数和出场顺序
#加载所需的R包
library(ggplot2)
library(data.table)
library(reshape2)
#设置文件路径
setwd("C:/Users/lenovo/Desktop/big data/倚天屠龙记分析")
#载入主角名单
roles = readLines("主角名单.txt")
roles[1:5]
#运行结果
[1] "殷离 蛛儿 表妹 丑姑娘 丑八怪"
[2] "周芷若 芷若 周姑娘 周掌门 周师妹 周姊姊 宋夫人"
[3] "赵敏 郡主 小妖女 敏妹 敏敏 赵姑娘"
[4] "小昭 小丫头"
[5] "张无忌 无忌 曾阿牛 阿牛哥 公子 张教主"
首先,我们来看一看人物的出场次数,这涉及到R语言的简单的文本分析。
#载入小说文本数据
yitian = readLines("倚天屠龙记.txt")
#将原小说进行分段
para_head = grep("\\s+", yitian, perl = T)
cut_para1 = cbind(para_head[1:(length(para_head)-1)], para_head[-1]-1)
yitian_para = sapply(1:nrow(cut_para1), function(i) paste(yitian[cut_para1[i,1]:cut_para1[i,2]], collapse = ""))
writeLines(yitian_para, "C:/Users/lenovo/Desktop/big data/倚天屠龙记分析/yitian_para.txt")
#对角色进行统计
roles1 = paste0("(", gsub(" ", ")|(", roles), ")")
roles_l = strsplit(roles, " ") # 总结每个人的不同称呼
#计算每个人物名称的出现次数
role_para = sapply(roles1, grepl, yitian_para)
colnames(role_para) = sapply(roles_l, function(x) x[1])
#将角色出现次数赋值到一个数据框中以便作图
role_count = data.frame(role = factor(colnames(role_para),
levels = colnames(role_para)[order(colSums(role_para), decreasing = T)]),
count = colSums(role_para))
#根据出现次数绘图
ggplot(role_count, aes(x = role, y = count, fill = role)) +
geom_bar(stat = "identity", width = 0.75) +
xlab("Role") +
ylab("Count") +
theme(axis.text=element_text(size=30, angle = 90),
axis.title=element_text(size=20,face="bold"),
axis.title.x = element_text(vjust=-2),
legend.position="none")
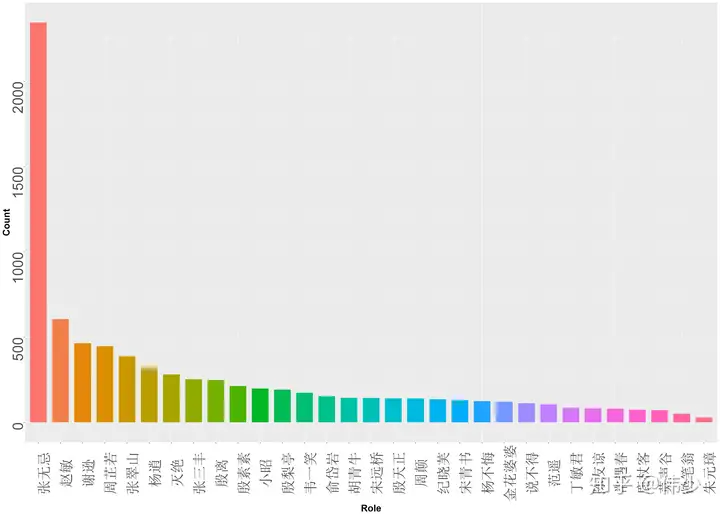
图1-1 人物角色的出现次数
显而易见,第一大主角就是张无忌,其他主要角色还有赵敏、周芷若、谢逊等。
接下来,我们研究一下各个人物的出场次序。
#将人物出场顺序放入数据框中以便作图
main_roles = c("殷离","周芷若","赵敏","小昭", "张无忌")
role_para_df = data.frame(role = factor(rep(main_roles, colSums(role_para)[1:5])),
para = which(role_para[,(1:5)], arr.ind = T)[,1])
#提取出三个主角的出场顺序
role_para_df1 = role_para_df[is.element(role_para_df$role, c("赵敏","周芷若", "张无忌")),]
#作出三个主角的出场顺序密度图
(p<-ggplot(role_para_df1, aes(para, fill = role, fill = role)) +
geom_density(aes(y = ..density..), alpha=I(0.3), color="white" ,size = 0) +
labs(x="\n出场顺序",y="密 度\n") +
scale_fill_manual("角 色",values=terrain.colors(7)[3:1]) +
theme(plot.margin = unit(c(0,1,1,0), "cm"),
axis.text=element_text(size=30),
axis.title.x = element_text(vjust=-2),
axis.title.y = element_text(),
axis.title=element_text(size=30,face="bold"),
panel.background = element_rect(fill="white"),
panel.grid.major = element_line(color="white"),
panel.grid.minor = element_line(color="white"),
axis.line = element_line(color="grey40"),
legend.key.size = unit(0.8,"cm"),
legend.text = element_text(size = 25),
legend.title = element_text(size = 25)))
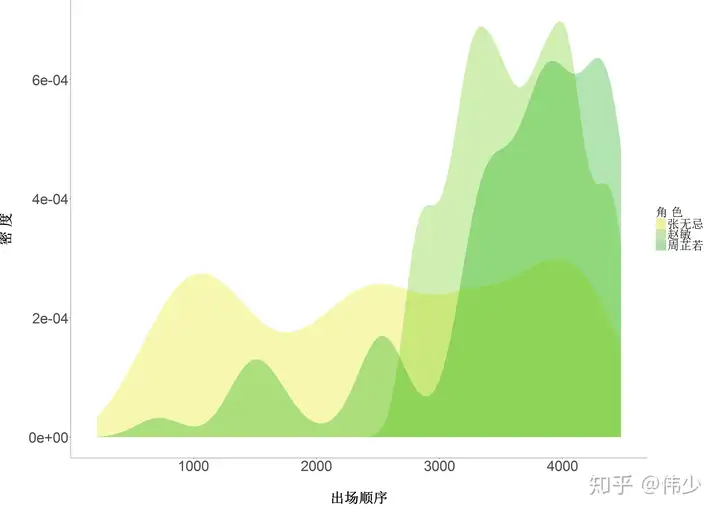
图1-2 三大主角的出场顺序密度图
从图1-2 中可以看出,张无忌这个角色贯穿整个小说,这和我们在电视上看到的是一样;赵敏在小说前一部分出现的频率并不多,在后一部分则成了NO.1;周芷若这个角色虽然也贯穿整个小说,但是出现频率忽高忽低,且在最后一部分(估计也就是练成九阴白骨爪那一刻)出现频率猛增。那接下我们得分析一下,到底张无忌和谁最亲近呢?
2. 计算前五个角色的亲密度矩阵图
#计算亲密度逻辑值
co_para = crossprod(role_para)
#将无意义的矩阵对角线元素化为0
diag(co_para) <- 0
#构建前5个人物亲密度矩阵
intimacy_main <- co_para[1:5,1:5]
#调整数据组织形式以便画图
intimacy_main <- melt(intimacy_main)
#绘制亲密度矩阵图
(p <- ggplot(intimacy_main,aes(Var1,Var2,fill=value)) +
geom_tile(color="#32CD32") +
geom_text(data=intimacy_main,aes(Var2,Var1,label=value),size=13,color="black") +
scale_fill_gradient(low = "white", high = "#32CD32") +
xlab("") + ylab("") +
scale_x_discrete(expand=c(0,0),limits = c(张无忌,赵敏,周芷若,殷离,小昭))+
scale_y_discrete(expand=c(0,0),limits = c(张无忌,赵敏,周芷若,殷离,小昭)[5:1]) +
theme(legend.position="none",
axis.text.y = element_text(color="grey20",size=37),
axis.text.x = element_text(angle=90,color="grey20",size=37)))
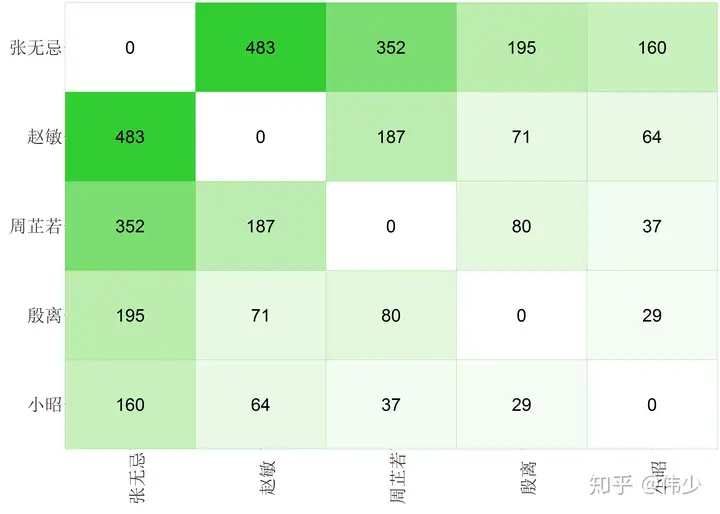
图2-1 主角的亲密度矩阵图
从图2-1 可以看出张无忌和赵敏最亲近,关系最密切;其次就是自己的儿时好友周芷若。
3. 主角不同称呼的出场顺序
#将不同人物分开
rolesl = strsplit(roles, " ")
#计算殷离不同称呼的出现段落
roles_para = sapply(rolesl[[1]], grepl, yitian_para)
colnames(roles_para) = rolesl[[1]]
#生成新数据框roles_para_df,罗列表示殷离不同称呼所出现的段落标号
roles_para_df = data.frame(role = factor(rep(colnames(roles_para), colSums(roles_para))),para = which(roles_para>0, arr.ind = T)[,1])
#根据殷离不同称呼绘制折线图
(p <- ggplot(roles_para_df, aes(para, fill = role)) +
geom_density(aes(y = ..density..), alpha=I(0.5), size = 0,color="white") +
labs(x="\n出现段落",y="密 度\n") + xlim(0, 4614)+
scale_fill_manual("称 谓",values=terrain.colors(6)[5:1]) +
theme(plot.margin = unit(c(0,1,1,0), "cm"),
axis.text=element_text(size=30),
axis.title.x = element_text(vjust=-2),
axis.title=element_text(size=30,face="bold"),
panel.background = element_rect(fill="white"),
panel.grid.major = element_line(color="white"),
panel.grid.minor = element_line(color="white"),
axis.line = element_line(color="grey40"),
legend.key.size = unit(1,"cm"),
legend.text = element_text(size = 25),
legend.title = element_text(size = 25)))
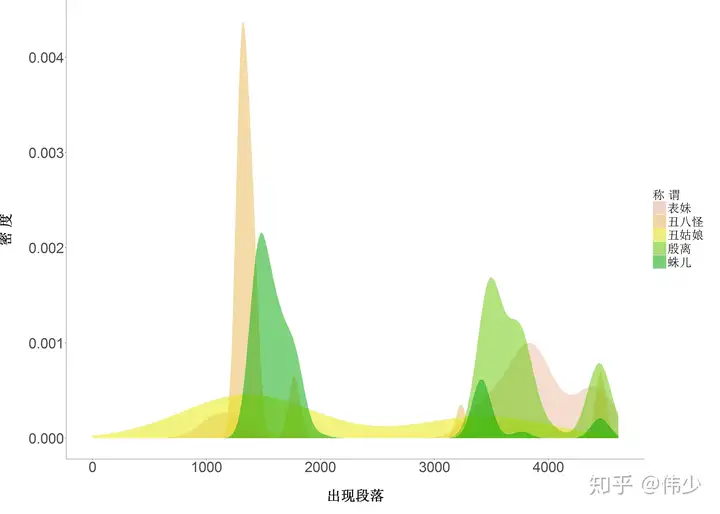
图3-1 蛛儿各个称谓的出场顺序的密度图
在第1000到2000这个段落之间,蛛儿主要以丑八怪和蛛儿的称呼出现,表明蛛儿此时间段正在练毒功,面目发生丑化,而且此时的张无忌正好称蛛儿为蛛儿,与我在电视剧中看到的大体一致;在3000到4000这个段落之间,蛛儿主要以殷离和表妹的称谓出现,可以说明蛛儿在最后和他爹殷野王相认,而张无忌作为殷野王的侄子自然改口叫蛛儿为表妹了,合情合理,略有成就感。
#计算周芷若不同名称的出现段落
roles_para = role_para[,5]*sapply(rolesl[[2]], grepl, yitian_para)[,c(2,3,4,7)]
colnames(roles_para) = rolesl[[2]][c(2,3,4,7)]
#生成新数据框roles_para_df,罗列表示周芷若不同称呼所出现的段落标号
roles_para_df = data.frame(role = factor(rep(colnames(roles_para), colSums(roles_para))),
para = which(roles_para>0, arr.ind = T)[,1])
#根据周芷若不同称呼绘制折线图
(p <- ggplot(roles_para_df, aes(para, fill = role)) +
geom_density(aes(y = ..density..), alpha=I(0.5), size = 0,color="white") +
labs(x="\n出现段落",y="密 度\n") + xlim(0, 4614)+
scale_fill_manual("称 谓",values=terrain.colors(6)[4:1]) +
theme(plot.margin = unit(c(0,1,1,0), "cm"),
axis.text=element_text(size=30),
axis.title.x = element_text(vjust=-2),
axis.title=element_text(size=30,face="bold"),
panel.background = element_rect(fill="white"),
panel.grid.major = element_line(color="white"),
panel.grid.minor = element_line(color="white"),
axis.line = element_line(color="grey40"),
legend.key.size = unit(1,"cm"),
legend.text = element_text(size = 25),
legend.title = element_text(size = 25)))
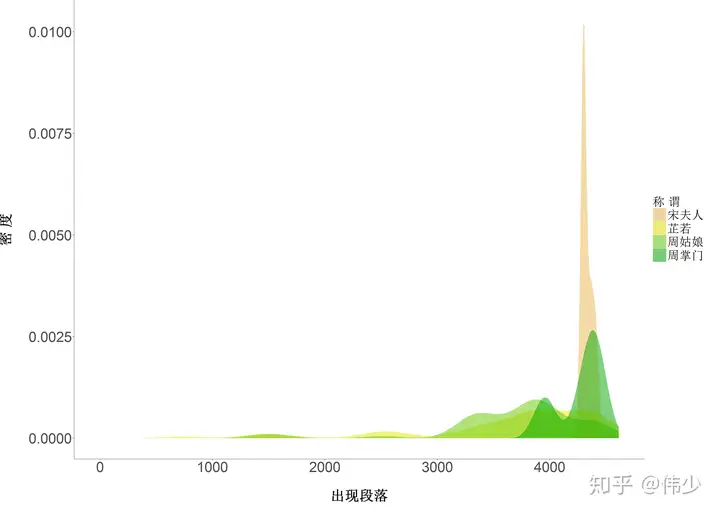
图3-2 周芷若各个称谓的出现顺序的密度图
从图3-2 可以看出周芷若的重头戏都在最后,且已经和张无忌的关系变得比较陌生了。
#计算赵敏不同称呼的出场段落
roles_para = role_para[,5]*sapply(rolesl[[3]], grepl, yitian_para)[,c(1,4,5,6)]
colnames(roles_para) = rolesl[[3]][c(1,4,5,6)]
#生成新数据框roles_para_df,罗列表示赵敏不同称呼所出现的段落标号
roles_para_df = data.frame(role = factor(rep(colnames(roles_para), colSums(roles_para))),
para = which(roles_para>0, arr.ind = T)[,1])
#根据赵敏不同称呼绘制折线图
(p <- ggplot(roles_para_df, aes(para, fill = role)) +
geom_density(aes(y = ..density..), alpha=I(0.5), size = 0,color="white") +
labs(x="\n出现段落",y="密 度\n") + xlim(2700, 4600)+
scale_fill_manual("称 谓",values=terrain.colors(6)[4:1]) +
theme(plot.margin = unit(c(0,1,1,0), "cm"),
axis.text=element_text(size=30),
axis.title.x = element_text(vjust=-2),
axis.title=element_text(size=30,face="bold"),
panel.background = element_rect(fill="white"),
panel.grid.major = element_line(color="white"),
panel.grid.minor = element_line(color="white"),
axis.line = element_line(color="grey40"),
legend.key.size = unit(1,"cm"),
legend.text = element_text(size = 25),
legend.title = element_text(size = 25)))
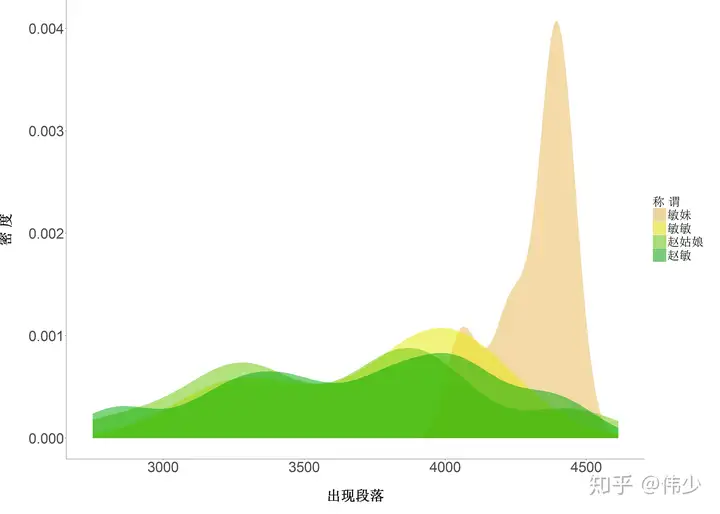
图3-3 赵敏各个称谓的出现顺序的密度图
图3-3 敏妹的直线增加也暗示了张无忌对赵敏的感情变化,也预示着他们两个走在了一起。
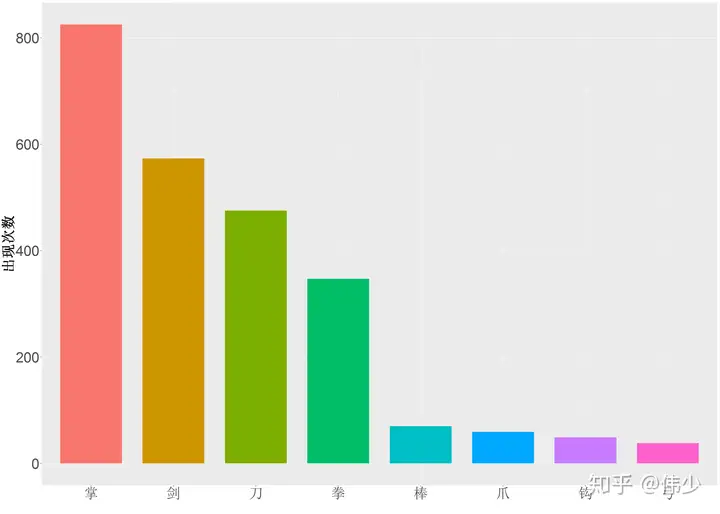
4. 倚天屠龙记中的武器分析
#分析兵器信息
(weapon = readLines("兵器.txt", encoding = "UTF-8")[-1])
yitian_para = readLines("yitian_para.txt")
weapon_para = sapply(weapon, grepl, yitian_para)
#计算各兵器出现次数
weaponN = colSums(weapon_para)
weapon_count_df = data.frame(weapon = factor(weapon, levels = weapon[order(weaponN, decreasing = T)]), count = weaponN)
#根据各种兵器的出现次数绘图
ggplot(weapon_count_df, aes(x = weapon, y = count, fill = weapon)) +
geom_bar(stat = "identity", width = 0.75) +
xlab("") + ylab("出现次数") +
theme(axis.text=element_text(size=30),
axis.title=element_text(size=30,face="bold"),
axis.title.x = element_text(vjust=-2),
legend.position="none")
#分析角色使用武功信息
roles1 = paste0("(", gsub(" ", ")|(", roles), ")")
rolesl = strsplit(roles, " "); roles_all = sapply(rolesl, function(x) x[1])
#将每个角色第一个称呼作为其主要称呼
role_para = sapply(roles1, grepl, yitian_para)
role_weapon = t(role_para)%*%weapon_para
rownames(role_weapon) = roles_all
role_weapon = 1/rowSums(role_weapon)*role_weapon
#计算主角使用不同武器的频率
role_weapon_df = data.frame(role = factor(rep(roles_all, length(weapon)), levels = roles_all),
weapon = factor(rep(weapon, each = length(roles_all)), levels = weapon),
value = as.vector(role_weapon))
#根据各主角使用不同武器频率进行绘图
maincharacter <- c("张无忌","殷离","赵敏","周芷若","小昭")
colorvector <- terrain.colors(7)[1:5]
#依次计算对主角使用不同武器频率
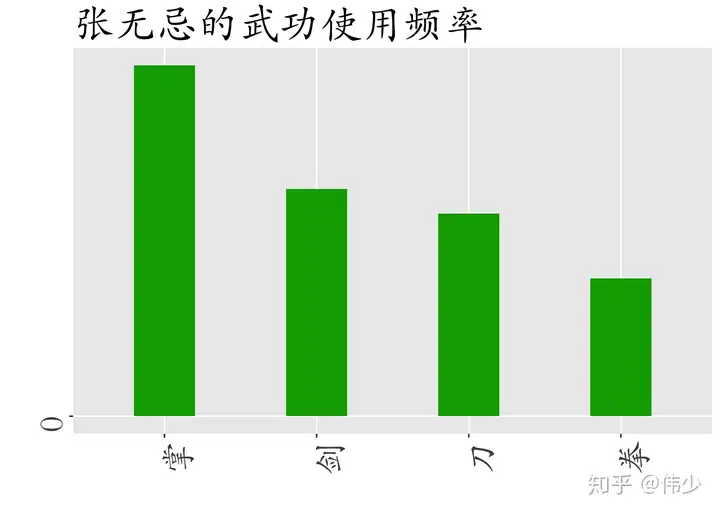
for(i in 1:length(maincharacter)){
role_weapon_temper <- subset(role_weapon_df,role_weapon_df$role==maincharacter[i])
role_weapon_temper <- role_weapon_temper[order(role_weapon_temper$value,decreasing = T),]
#按照从高到底顺序排列主角使用不同武器频率,依次做出四个角色使用武器频率图
p <- ggplot(role_weapon_temper,aes(x = weapon,y = value)) +
geom_bar(fill=colorvector[i],stat="identity",width=0.4) +
labs(x=" ",y=" ",title=paste(maincharacter[i],"的武功使用频率",sep="")) +
scale_x_discrete(limits = role_weapon_temper$weapon[order(role_weapon_temper$value,decreasing = T)][1:4]) +
scale_y_continuous(breaks = seq(from=0,to=500,by=100),labels = seq(from=0,to=0.5,by=0.1)) +
theme(panel.background=element_rect(fill="white"),
axis.line.x=element_line(color="grey70"),
axis.line.y=element_line(color="grey70"),
axis.text = element_text(size=30),
plot.title = element_text(size=30))
print(p)
}
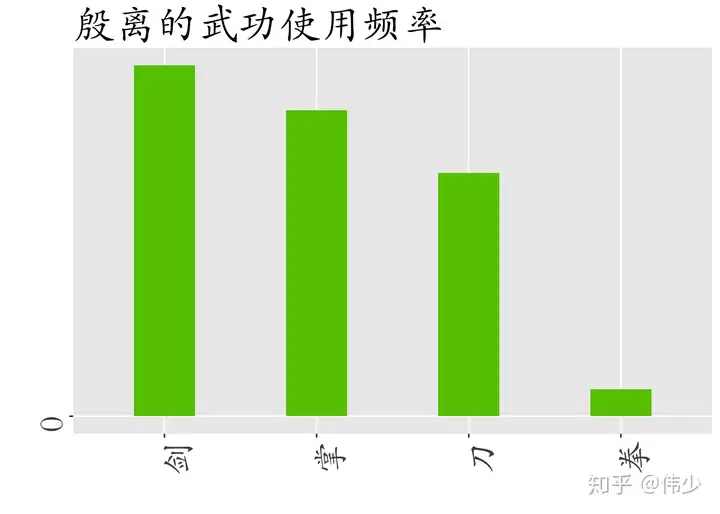
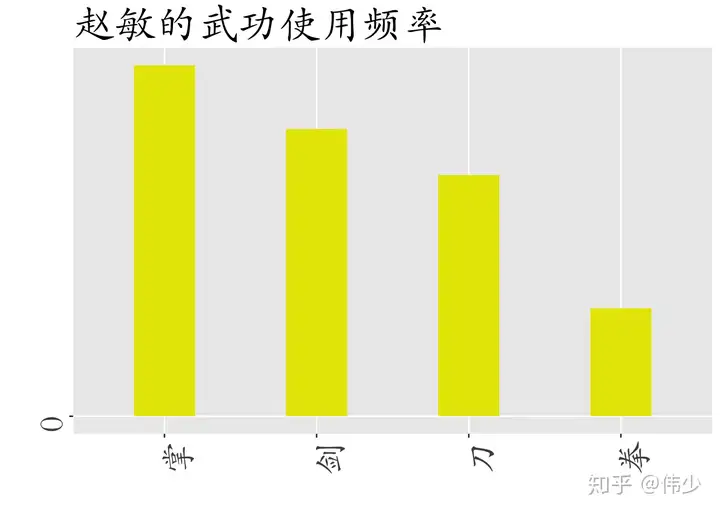

#四个门派各选取两个代表人物
people <- c("周芷若","灭绝师太","张三丰","张翠山","杨逍","张无忌","赵敏","鹤笔翁")
weapon_mp <- role_weapon_df[is.element(role_weapon_df$role,people),]
mp <- c("峨眉派","武当派","明教","郡主府")
#根据代表人物计算其各武器使用频率
colorvector <- terrain.colors(8)[1:7]
for(i in 1:4){ #依次计算代表人物武器使用频率
weapon_temp1 <- subset(weapon_mp,weapon_mp$role==people[2*i-1])
weapon_temp2 <- subset(weapon_mp,weapon_mp$role==people[2*i])
weapon_temp <- rbind(weapon_temp1,weapon_temp2)
#绘制条形图
(p <- ggplot(weapon_temp,aes(x = weapon,y = value,fill=factor(role))) +
geom_bar(width=0.5,stat = "identity",position = "dodge") +
scale_fill_manual("代表人物",values = c(colorvector[1],colorvector[4])) +
labs(x=" ",y=" ",title=paste(mp[i],"代表人物武功使用频率",sep="")) +
scale_y_continuous(breaks = seq(from=0,to=500,by=100),labels = seq(from=0,to=0.5,by=0.1)) +
theme(panel.background=element_rect(fill="white"),
axis.line.x=element_line(color="grey70"),
axis.line.y=element_line(color="grey70"),
axis.text = element_text(size=30),
plot.title = element_text(size=30),
legend.key.size = unit(1,"cm"),
legend.text = element_text(size = 25),
legend.title = element_text(size = 25)))
print(p)
}
5. 各个人物的社交网络图
#加载所需要的R包
library(igraph)
library(sna)
library(network)
library(ggraph)
#构造适用于gephi作图的数据social_net
#co_para为每两个人出现在同一段落的次数,将其中出现在同一段落的次数超过25次的两个角色定义为有联系
social_net=melt(co_para)
social_net=social_net[social_net$value>25,]
social_net$Type=rep("Undirected",nrow(social_net))
colnames(social_net)=c("Source","Target","Weight","Type")
social_net1 = graph_from_data_frame(social_net)
ggraph(social_net1,layout = "fr")+
theme_grey()+
geom_edge_link() +
geom_node_point() +
geom_node_text(aes(label = name), vjust = 1, hjust = 1)
这个图形比较乱,需要进行改进。
ggraph(social_net1, layout = "fr") +
geom_edge_link(aes(edge_alpha = Weight), show.legend = FALSE,
end_cap = circle(.07, inches)) +
geom_node_point(color = "green", size = 5) +
geom_node_text(aes(label = name), vjust = 1, hjust = 1,family="STKaiti") +
theme_void()
这个图形基本可以看出谁和谁的联系比较多,谁是剧中主要人物,谁是次要人物。不过,我们还可以进一步改进一下,给图形加上箭头:
set.seed(2019)
a <- grid::arrow(type = "closed", length = unit(.15, "inches"))
ggraph(social_net1, layout = "fr") +
geom_edge_link(aes(edge_alpha = Weight), show.legend = FALSE,
arrow = a, end_cap = circle(.07, inches)) +
geom_node_point(color = "green", size = 5) +
geom_node_text(aes(label = name), vjust = 1, hjust = 1,family="STKaiti") +
theme_void()
#输出可用于gephi作图的边数据social_net
write.csv(social_net,file = "social_net.csv")
#网络统计量计算#
#将co_para变为01邻接矩阵
a=matrix(0,31,31)
a=(co_para>25)*1
a=a[!colSums(a)==0,!rowSums(a)==0]
#构造图对象
g <- graph.adjacency(a,mode = "undirected")
#顶点数
length(V(g)) #结果是30个人
#边数
length(E(g)) #91条边
#网络密度计算方法1
graph.density(g) #0.2091954
#网络密度计算方法2
sum(a!=0)/(nrow(a)*(nrow(a)-1)) #0.2091954
#度分布直方图
par(cex.lab = 1,cex.main = 2)
#a.r为度数分布向量
a.r = rowSums(a)
hist(a.r, col = "#32CD32",xlab="度数",ylab="频数",main="度数分布图",breaks = 20,xlim=c(0,30))
text(27,2,"张无忌",cex=1)
text(15.5,1.5,"赵敏",cex=1)
text(12,1.5,"周芷若",cex=1)
mean(a.r) #6.066667
#平均度数6.07,即平均每个人都与另外6个人有联系
6. 层次聚类
#加载所需R包
library(jiebaR)
library(wordVectors)
library(ape)
#注意wordVectors包需要用devtools::install.github函数下载
#代码如下
#install.packages("devtools")
#library(devtools)
#install_github("bmschmidt/wordVectors")
#根据词语将整本小说分成不同字符串
cutter = worker(bylines = TRUE, stop_word = "stop.txt")
#根据主角名称进行分词
new_user_word(cutter, unlist(rolesl), rep("n", length(unlist(rolesl))))
#输出分词后的段落文本
yitian_words = cutter[yitian_para]
yitian_split = sapply(yitian_words, paste, collapse = " ")
writeLines(yitian_split, "yitian_split.txt")
#训练词向量
model = train_word2vec("yitian_split.txt", output="yitian_split.bin",
threads = 3, vectors = 100, window=12, force = T)
vec = read.vectors("yitian_split.bin")
#计算和三位主角共同出现次数最多的词语
nearest_to(model,model[["张无忌"]])
nearest_to(model,model[["赵敏"]])
nearest_to(model,model[["周芷若"]])
#提取出所有主角
rr = sapply(rolesl, function(x) x[1])
cos_dist = cosineDist(vec[rr,],vec[rr,])
#计算其不同人物词语向量化后的cos夹角
hc = hclust(as.dist(cos_dist), method = "average")
#设置颜色向量以便画图
colorvec <- c("white","#F36838","#90FFFF","#C0EBD7","#FFC773","#CCA4E3","#D3B17D")
#设置图片背景颜色
op = par(bg = "grey20")
class <- cutree(hc,7)
#利用ape包将hc对象转为phylo对象,并绘制分类图
plot(as.phylo(hc),type="fan",
tip.color=colorvec[class],
edge.color="#C0EBD7",
cex=3,
edge.width=3)