好好学习,天天向上
本文已收录至我的Github仓库DayDayUP:
github.com/RobodLee/DayDayUP,欢迎Star
畅购商城(一):环境搭建畅购商城(二):分布式文件系统FastDFS
畅购商城(三):商品管理畅购商城(四):Lua、OpenResty、Canal实现广告缓存与同步畅购商城(五):Elasticsearch实现商品搜索畅购商城(六):商品搜索畅购商城(七):Thymeleaf实现静态页
畅购商城(八):微服务网关和JWT令牌畅购商城(九):Spring Security Oauth2畅购商城(十):购物车畅购商城(十一):订单畅购商城(十二):接入微信支付畅购商城(十三):秒杀系统「上」 代码:
github.com/RobodLee/changgou
前期准备
今天的任务就是用ElasticSearcher实现商品搜索的功能。关于Elasticsearch、IK分词器、Kibana的安装及基本使用可以看我的另一篇文章Elasticsearch入门指南。
搜索微服务的API工程的搭建
在changgou-service-api下创建一个Module叫changgou-service-search-api。我们后面所要是实现的功能都是基于Spring Data ElasticSearch实现的,所以相关依赖不能少:
<dependencies>
<!--goods API依赖-->
<dependency>
<groupId>com.robod</groupId>
<artifactId>changgou-service-goods-api</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<!--SpringDataES依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
</dependencies>
搜索微服务搭建
在changgou-service下新建一个changgou-service-search工程作为搜索微服务。在搜索微服务里面需要用到API工程的JavaBean和Feign接口,所以将search-api和goods-api作为依赖添加进来。
<dependencies>
<!--依赖search api-->
<dependency>
<groupId>com.robod</groupId>
<artifactId>changgou-service-search-api</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>com.robod</groupId>
<artifactId>changgou-service-goods-api</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
</dependencies>
启动类和配置文件自然不能少
@SpringBootApplication(exclude={DataSourceAutoConfiguration.class})
@EnableEurekaClient
@EnableFeignClients(basePackages = "com.robod.goods.feign")
@EnableElasticsearchRepositories(basePackages = "com.robod.mapper")
public class SearchApplication {
public static void main(String[] args) {
//解决SpringBoot的netty和elasticsearch的netty相关jar冲突
System.setProperty("es.set.netty.runtime.available.processors", "false");
SpringApplication.run(SearchApplication.class,args);
}
}
server:
port: 18085
spring:
application:
name: search
data:
elasticsearch:
cluster-name: my-application # 集群节点的名称,就是在es的配置文件中配置的
cluster-nodes: 192.168.31.200:9300 # 这里用的是TCP端口所以是9300
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:7001/eureka
instance:
prefer-ip-address: true
feign:
hystrix:
enabled: true
#超时配置
ribbon:
ReadTimeout: 500000 # Feign请求读取数据超时时间
hystrix:
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 50000 # feign连接超时时间
数据导入ES
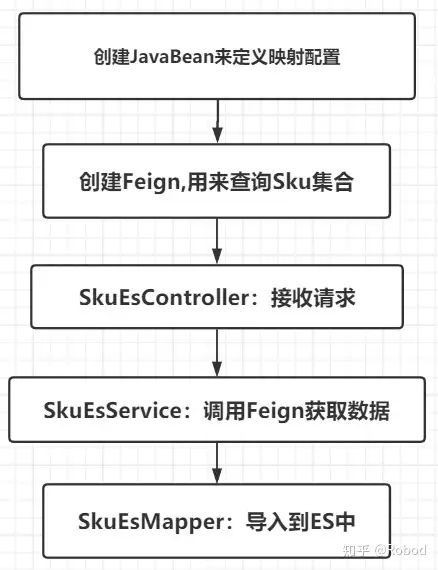
数据从MySQL导入到ES中大概分为以下几个步骤:
首先我们需要去创建一个JavaBean来定义相关的映射配置,Index,Type,Field。在changgou-service-search-api的com.robod.entity包下创建一个JavaBean叫SkuInfo:
@Data
@Document(indexName = "sku_info", type = "docs")
public class SkuInfo implements Serializable {
@Id
private Long id;//商品id,同时也是商品编号
/**
* SKU名称
* FieldType.Text支持分词
* analyzer 创建索引的分词器
* searchAnalyzer 搜索时使用的分词器
*/
@Field(type = FieldType.Text, analyzer = "ik_smart",searchAnalyzer = "ik_smart")
private String name;
@Field(type = FieldType.Double)
private Long price;//商品价格,单位为:元
private Integer num;//库存数量
private String image;//商品图片
private String status;//商品状态,1-正常,2-下架,3-删除
private LocalDateTime createTime;//创建时间
private LocalDateTime updateTime;//更新时间
private String isDefault; //是否默认
private Long spuId;//SPU_ID
private Long categoryId;//类目ID
@Field(type = FieldType.Keyword)
private String categoryName;//类目名称,不分词
@Field(type = FieldType.Keyword)
private String brandName;//品牌名称,不分词
private String spec;//规格
private Map<String, Object> specMap;//规格参数
}
在SkuInfo中,设置了Index是"sku_info",Tpye为"docs",并为几个字段设置了分词。然后在changgou-service-goods-api的com.robod.goods.feign包下创建一个Feign的接口SkuFeign:
@FeignClient(name = "goods")
@RequestMapping("/sku")
public interface SkuFeign {
/**
* 查询所有的sku数据
* @return
*/
@GetMapping
Result<List<Sku>> findAll();
}
我们将使用这个Feign去调用Goods微服务中的findAll方法去数据库中获取所有的Sku数据。最后,在changgou-service-search微服务中写出Controller,Service,Dao层的相关代码,实现数据导入的功能。
//SkuEsController
@GetMapping("/import")
public Result importData(){
skuEsService.importData();
return new Result(true, StatusCode.OK,"数据导入成功");
}
-----------------------------------------------------------
//SkuEsServiceImpl
@Override
public void importData() {
List<Sku> skuList = skuFeign.findAll().getData();
List<SkuInfo> skuInfos = JSON.parseArray(JSON.toJSONString(skuList), SkuInfo.class);
//将spec字符串转化成map,map的key会自动生成Field
for (SkuInfo skuInfo : skuInfos) {
Map<String,Object> map = JSON.parseObject(skuInfo.getSpec(),Map.class);
skuInfo.setSpecMap(map);
}
skuEsMapper.saveAll(skuInfos);
}
-------------------------------------------------------------
//继承自ElasticsearchRepository,泛型为SkuInfo,主键类型为Long
public interface SkuEsMapper extends ElasticsearchRepository<SkuInfo,Long> {
}
现在将程序运行起来,访问http://localhost:18085/search/import就可以开始导入了。
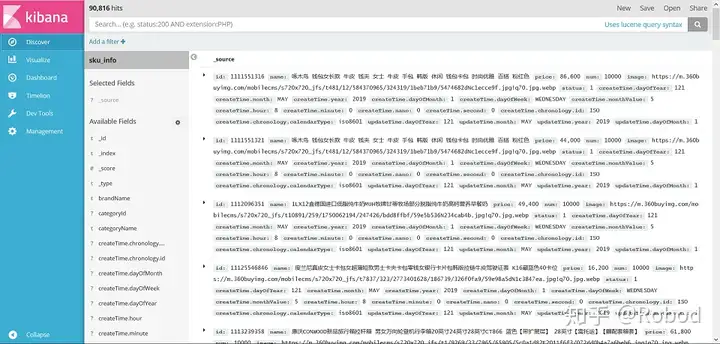
经过漫长的等待之后,9万多条数据成功导入到ES中了。耗费的时间有点长,大概十五分钟,可以是和虚拟机的配置有关吧。
当我做完这个的时候就提交到Github上了,后来我改来改去的,改乱了就退回到之前提交的版本。然后启动项目就报了一个错说Bean注入失败,我就纳闷了,我这是之前提交的正常的版本,怎么就出问题了。然后仔细地翻了翻日志,发现有一行
这个貌似是索引出了问题,删除索引,启动项目,没问题了,重新导入数据到ES,搞定!
功能实现
根据关键词搜索
在开始实现这个功能之前,得先规定好前后端传参的格式。视频中用的是Map,但我觉得Map不好,可读性太差了。比较好的做法是封装一个实体类,所以我在search-api工程中添加了一个SearchEntity作为前后端传参的格式:
@Data
public class SearchEntity {
private long total; //搜索结果的总记录数
private int totalPages; //查询结果的总页数
private List<SkuInfo> rows; //搜索结果的集合
public SearchEntity() {
}
public SearchEntity(List<SkuInfo> rows, long total, int totalPages) {
this.rows = rows;
this.total = total;
this.totalPages = totalPages;
}
}
然后就是在搜索微服务中写出相应的代码了
@GetMapping
public Result<SearchEntity> searchByKeywords(@RequestParam(required = false)String keywords) {
SearchEntity searchEntity = skuEsService.searchByKeywords(keywords);
return new Result<>(true,StatusCode.OK,"根据关键词搜索成功",searchEntity);
}
---------------------------------------------------------------------------------------------------
@Override
public SearchEntity searchByKeywords(String keywords) {
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();
if (!StringUtils.isEmpty(keywords)) {
nativeSearchQueryBuilder.withQuery(QueryBuilders.queryStringQuery(keywords).field("name"));
}
AggregatedPage<SkuInfo> skuInfos = elasticsearchTemplate
.queryForPage(nativeSearchQueryBuilder.build(), SkuInfo.class);
List<SkuInfo> content = skuInfos.getContent();
return new SearchEntity(content,skuInfos.getTotalElements(),skuInfos.getTotalPages());
}
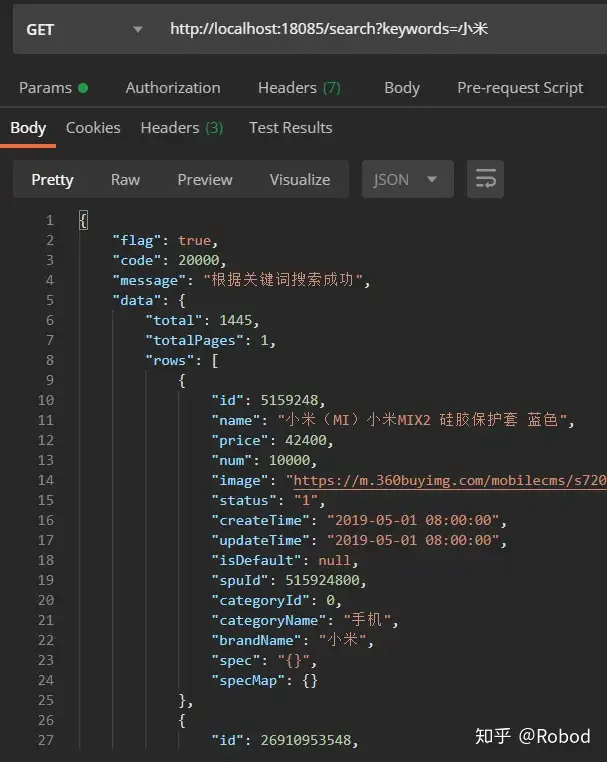
然后将项目启动起来,访问http://localhost:18085/search?keywords=小米,结果报错了,报了一个failed to map,然后我在报错信息中找到了下面这个:
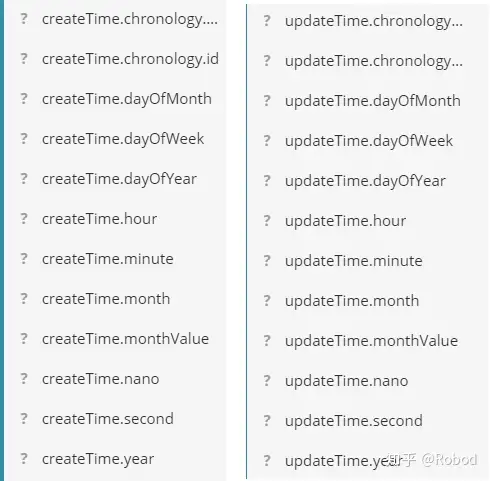
大概意思就是LocalDateTime出了问题,因为Date类不是很好,所以我就改成了LocaDateTime。我看了一下Kibana中的内容,发现
原来是ES自动把LocalDateTime分成了多个Filed,可是我不想让它分成多个Filed,也不想用Date,怎么办呢?我在网上找个一个方法,成功解决了我的问题,就是增加 @JsonSerialize 和 @JsonDeserialize 注解,所以我在SkuInfo的createTime和updateTime上面加了几个注解:
/**
* 只用后两个注解就可以实现LocalDateTime不分成多个Field,但是格式不对。
* 所以还需要添加前面两个注解去指定格式与时区
**/
@Field(type = FieldType.Date, format = DateFormat.custom, pattern = "yyyy-MM-dd HH:mm:ss || yyyy-MM-dd")
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
@JsonSerialize(using = LocalDateTimeSerializer.class)
@JsonDeserialize(using = LocalDateTimeDeserializer.class)
private LocalDateTime createTime;//创建时间
@Field(type = FieldType.Date, format = DateFormat.custom, pattern = "yyyy-MM-dd HH:mm:ss || yyyy-MM-dd")
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
@JsonSerialize(using = LocalDateTimeSerializer.class)
@JsonDeserialize(using = LocalDateTimeDeserializer.class)
private LocalDateTime updateTime;//更新时间
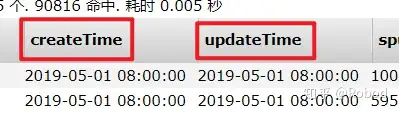
现在再次重新导入一下
现在格式没有问题了,现在再来测试看看
OK!
分类统计
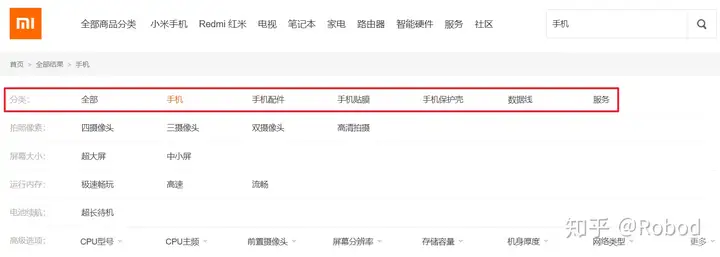
当我们在小米商城上面搜索一件商品的时候,下面会将分类展示出来帮助用户进一步地筛选产品。在畅购商城的表设计中,也有一个叫categoryName的字段。接下来就是要实现把我们搜索出来的数据进行分类统计。
我们要实现的就是图中的效果,只不过是在Elasticsearch中而不是MySQL。
修改SearchEntity,添加一个categoryList字段:
private List<String> categoryList; //分类集合
修改SkuEsServiceImpl中的searchByKeywords方法,添加分组统计的的代码:
public SearchEntity searchByKeywords(String keywords) {
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();
if (!StringUtils.isEmpty(keywords)) {
nativeSearchQueryBuilder.withQuery(QueryBuilders.queryStringQuery(keywords).field("name"));
//terms: Create a new aggregation with the given name.
nativeSearchQueryBuilder.addAggregation(AggregationBuilders.terms("categories_grouping")
.field("categoryName"));
}
NativeSearchQuery nativeSearchQuery = nativeSearchQueryBuilder.build();
AggregatedPage<SkuInfo> skuInfos = elasticsearchTemplate.queryForPage(nativeSearchQuery, SkuInfo.class);
StringTerms stringTerms = skuInfos.getAggregations().get("categories_grouping");
List<String> categoryList = new ArrayList<>();
for (StringTerms.Bucket bucket : stringTerms.getBuckets()) {
categoryList.add(bucket.getKeyAsString());
}
return new SearchEntity(skuInfos.getTotalElements(),skuInfos.getTotalPages(),
categoryList,skuInfos.getContent());
}
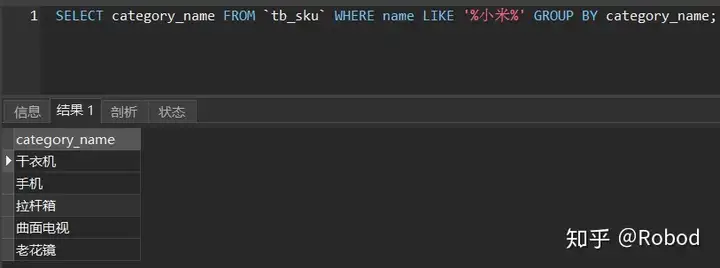
现在再来测试一下:
OK!分组统计的功能已经实现了。
小结
这篇文章主要写了Elasticsearch环境的搭建,然后把数据导入到ES中。最后实现了关键词搜索以及分类统计的功能。
如果我的文章对你有些帮助,不要忘了点赞,收藏,转发,关注。要是有什么好的意见欢迎在下方留言。让我们下期再见!