阅读笔记:双塔结构
一、语义召回模型-TwinBert - 简书 (jianshu.com)
评:我司的经典算法,你值得拥有。
输入 : 均为Word Embeding + Position Embeding。 因为两边都是一句话,所以就没有了Segment Embeding了
评:改良的Bert,删掉了一些无意义的输入。
值得提一下是,论文中是训练的英文的模型,所对输入进行了Word Hashing,具体说是使用了Tri-letter, 至于什么是Word Hashing ,见本人的另外一文章Word Hashing。
评:和CDSSM一脉相承,对拉丁语系有用,不过对中文没有用,还得用分词、词典映射那一套。
二、久别重逢话双塔 - 知乎 (zhihu.com)
只不过“部署时分离”成了双塔最大的优点,而“训练时分离”成了制约双塔性能的最大因素。
user侧信息与item侧信息,只有唯一一次交叉机会,就是在双塔生成各自的embedding之后的那次点积或cosine。但是这时参与交叉的user/item embedding,已经是高度浓缩的了。一些细节信息已经损失,永远失去了与对侧信息交叉的机会。
评:确实,单塔64维的输出能够反映的信息已经很少了。
我们要特别注意那些“极其个性化”(e.g., userId, itemId)的特征,和,对划分人群、物群有显著区分性的特征(e.g., 用户是新用户还是老用户?用户是否登陆?文章所使用的语言,等)。
评:大数据时代,数据(数据源、特征)在实际项目中往往更重要。
传统双塔不是交叉太晚吗?那我就发挥深度学习“无中生有”的优点,在user侧“造”出一个embedding模拟item tower的输出,并作为特征接入user tower的最底层。
评:没看懂,可以看看原论文。
三、张俊林:对比学习在微博内容表示的应用 (qq.com)
好的对比学习系统实际上包含两方面要素:Alignment和Uniformity。Alignment指相似实例有相近的特征,在映射之后,距离相近;Uniformity指的是模型应该保留尽可能多的信息,输入数据在经过映射之后,在单位超球面上的分布尽可能均匀。模型坍塌是一种极度的分布不均匀,所以使得样本在投影空间分布均匀可以解决模型坍塌问题,这可以理解为:分布均匀使得每个个体例子保留了自己的个体信息,均匀的本质是促使样例在经过编码和投影之后尽可能保留更多个性信息。
评:确实。
一个抽象的对比学习系统的构造方式如下:首先,利用自监督方式,构造好一些正例,一些负例(即正样本,负样本);之后,将样本输入encoder进行编码;然后,将样本编码之后的结果投影到一个单位超球面。
对比学习系统的优化目标是:如果输入样本为正例,则希望在投影空间中样本之间的embedding越近越好,反之,为负例时两者距离越远越好。
评:张博这样方便理解,但是也有个天然的漏洞,那就是负例真的是两者距离越远越好吗?如果两者角度是180度那么两者是负相关还是不相关?我在项目中感觉负例更多像90度这样的情况,更多像混沌那种状态。
四、NLP | DSSM双塔模型类综述 - 简书 (jianshu.com)
微软的学者们又提出了一个观点:query与doc的相关程度是由query里的term与doc文本精准的匹配,以及query语义与doc语义匹配程度共同决定。
评:确实,大家在用Bert提取语义特征的时候也不要忘了特征抽取这些老方法啊。
五、做向量召回 All You Need is 双塔 - 知乎 (zhihu.com)
但是Mobius的这种将商业指标(CTR*bid)提前引入召回阶段的思想是非常具有探索价值的,比如文章中提到将cosine相似度直接乘上一个商业指标作为系数,就是一个很简单的方式。
评:有新意。
六、DistillBert: Bert太贵?我便宜又好用 - 知乎 (zhihu.com)
同时为了避免老师也有出错的时候,学生也会对目标标签进行学习,这也就是图中的student loss(也是hard targets)。
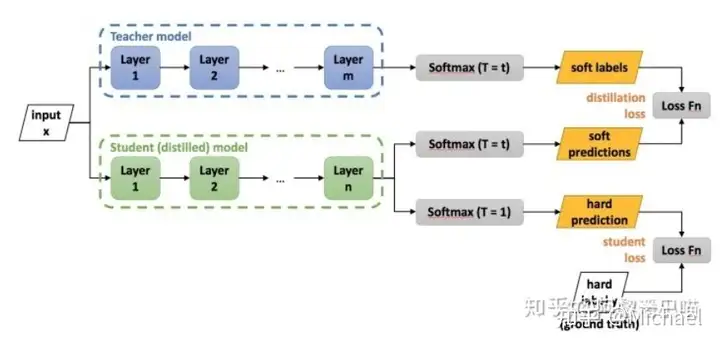
评:soft label和hard targets的结合可以值得一试。就是不知道两个数据集的比例是多少。另外,为什么不直接用soft labels训练,再在hard labels上finetune?
在GLUE上的效果,DistillBert的效果比Bert平均差3~5个点
评:student model确实比teacher model要差点。
七、预训练技术在美团到店搜索广告中的应用 (qq.com)
搜索广告在优化流量变现效率等商业指标之外,也需要重点优化用户体验,降低不相关广告对用户体验的损害,这样才能保证平台生态的健康发展。
评:确实,保证利润的同时,广告的defect rate也不能太高。
在优化用户体验的目标下,如何正确的衡量用户体验,定义不相关广告是首要解决的问题。在搜索广告中,受结果列表页广告位置偏差、素材创意等因素影响,我们无法单一使用点击率(CTR)等客观性指标来衡量用户体验,尤其首位、首屏等排序靠前广告的相关性问题被认为是影响用户体验的主要因素。我们首先建立了美团场景下的搜索广告相关性标准和评估体系,主要通过例行采样和人工评估的方式对搜索广告结果进行相关、一般和不相关的分档标注,进而驱动我们的广告相关性模型和策略迭代。然后,使用广告排序前五位的Badcase率(即Badcase@5)作为搜索广告的相关性评估指标。
评:目标是减少不相关广告,这种情况下确实人工打分是最有效的。
针对搜索语义匹配任务,Google[3]和Bing[4]的搜索团队已经基于BERT来编码Query和候选Doc,进而改善相关性的效果。
评:Wenhao Lu大佬牛逼
针对上述问题,在第二阶段任务型知识蒸馏过程中,我们提出了虚拟交互机制(Virtual InteRacTion mechanism, VIRT),如图4(d)所示,通过在双塔结构中引入虚拟交互信息,将交互模型中的知识迁移到双塔模型中,从而在保持双塔模型性能的同时提升模型效果。
评:好多论文都是这个思路,把交互提前。
为了更好地衡量广告召回结果的相关程度,除了基于模型得出的语义相关性之外,我们还计算了文本相关性、类目相关性等分数,并对所有分数进行融合得到最终的相关性分数。
评:实际项目确实得这样。
八、负样本为王:评Facebook的向量化召回算法 (qq.com)
缺乏置信度高的离线评测手段仍然是召回工作中的痛点。
评:确实,线上flight耗时耗力。
离线训练数据的分布,应该与线上实际应用的数据,保持一致。
排序其目标是“从用户可能喜欢的当中挑选出用户最喜欢的”,是为了优中选优。与召回相比,排序面对的数据环境,简直就是温室里的花朵。召回是“是将用户可能喜欢的,和海量对用户根本不靠谱的,分隔开”,所以召回在线上所面对的数据环境,就是鱼龙混杂、良莠不齐。评:确实,对于召回,负样本应该是样本库里的99%的文本,大多数的文本是不会被用户喜欢的。
所以文章中描述的基本版本就是拿点击样本做正样本,拿随机采样做负样本。因为线上召回时,候选库里大多数的物料是与用户八杆子打不着的,随机抽样能够很好地模拟这一分布。
评:随机采样有点用,但是大部分都是easy negative。
九、是"塔"!是"塔"!就是它,我们的双塔! - 云+社区 - 腾讯云 (tencent.com)
文章对双塔的论文有一些总结,可以看看其观点。
十、召回:是"塔",是"塔",但不是双塔! - 云+社区 - 腾讯云 (tencent.com)
query到doc这种文本到文本的召回,通常就是各种双塔召回,再排序的过程.谷歌这篇论文<Transformer Memory as a Differentiable Search Index>却偏不.这篇论文提出了Differentiable Search Index(DSI)的方法,直接就把docid编码到了模型中,output直接就是docid,不需要像以往那样还要建立docid到向量的索引再ANN召回.这样在结果上显著优于双塔.
评:有时间可以看看。
十一、SENet双塔模型:在推荐领域召回粗排的应用及其它 (qq.com)
双塔结构不是一种具体的模型结构,而是一种抽象的模型框架。
评:赞同,从DSSM到CDSSM再到TwinBert,encoder的模型变了,但双塔的结构及线上建立索引的思想一直没变。
另外一种思路是知识蒸馏,也就是说,召回和粗排环节做为Student,学习精排Teacher的排序偏好,等于说前置环节,直接学习精排的优化目标,打通整个通路。当然,知识蒸馏除了能够引导推荐系统各个环节优化目标保持一致,还可以通过复杂Teacher传播复杂模型和特征给前置环节,提高前置环节模型效果。知识蒸馏具体做法有很多,可以参考:知识蒸馏在推荐系统的应用, 这里不再赘述。
评:有意思。补充的一点是,召回和精排的场景有点差别,除了要找到好的候选样本外,还要筛选掉海量差的样本。
十二、索引Index、ANN最近邻搜索
因为双塔结构一般都会讲doc端线下计算好,建立索引,线上则用ANN搜索,这里一并记录下。
参考(38条消息) 图像检索之product quantization 算法解析_gswen的博客-CSDN博客
图像匹配的本质就是比较向量的相似程度。现在主要是通过比较向量的欧式距离来比较他们的相似成都。比较过程就是对于一个输入向量,在数据库中找到与其在欧式空间上距离最近的向量。因此,朴素的算法是对数据库中的特征向量进行遍历。因此要找到最邻近的匹配值,起码都要把所有的向量比较一遍。但有两个问题,一个是数据库中一般含有的特征向量数目非常多,起码都是千万级别的,因此遍历一遍会花很多时间;其次,计算向量之间的欧式距离也是一个花销非常大的过程。
因此提出了近邻最邻近算法(Approximate nearest neighbor,ANN),ANN算法的目的不是寻找最邻近向量,而是近似最邻近向量。
ANN算法的核心思想是先建立code book,然后将特征向量量化到code word上,最后通过比较对应的code word的距离即可,可以认为被量化到同一个code word上的特征是近似最邻近的。缺点是存在量化误差——可能会把欧式空间中相邻的特征量化到不同的code word上。
Product quantization是量化算法中一种比较好的算法。其允许将一个向量的各个部分进行分开量化。优势在于,通过对将较小的几个code book连接形成一个规模足够大的codebook。而且对于小的codebook,训练复杂度相对直接训练大的codebook是低的多的。所以根据这个原理,直接存储C个codebook是没必要的,且相反会降低最终的量化速率。因此在存储的时候,我们采用的是分别存储m个大小为k*的codebook的方式。
而faiss是一个比较成熟的开源库了,可参考揭开Faiss的面纱 探究Facebook相似性搜索工具的原理 | 雷峰网 (leiphone.com)和facebook Faiss的基本使用示例(逐步深入)_sparkexpert的博客-CSDN博客_faiss。
Faiss是在十亿级数据集上创建的最近邻搜索(nearest neighbor search),比此前的最前沿技术快8.5倍,并创造出迄今为止学术圈所见最快的、运行于GPU的k-selection算法。许多索引算法库针对的是百万左右的矢量,Facebook的工程师们把这当成小规模。
在CPU方面:
多线程以充分利用多核性能并在多路GPU上进行并行搜索; BLAS算法库通过matrix/matrix乘法进行高效、精确的距离计算; 机器SIMD矢量化和popcount被用于加速孤立矢量的距离计算;在GPU方面:
中间状态都完全保存在寄存器中,进一步提升速度; 它能够将输入数据以 single pass 进行 k-select,运行于潜在峰值性能的 55%,取决于峰值 GPU 显存带宽。由于其状态只存储在注册表中,并可与其他 kernels 融合,使它成为超级快的 exact 和 approximate 搜索引擎; 通过使用IndexIVFFlat索引,将数据集分割成多个,在d维空间中定义Voronoi单元,每个数据库向量落在其中一个单元格中。用了faiss.IndexFlatL2来建立index,这样可以储存完整的变量。到非常大的数据集时,Faiss提供了基于产品量化器的有损压缩来压缩存储的向量的变体,压缩的方法基于乘积量化。
微软开源的ANN是GitHub - microsoft/SPTAG: A distributed approximate nearest neighborhood search (ANN) library which provides a high quality vector index build, search and distributed online serving toolkits for large scale vector search scenario.,可以尝试一下。
简单的介绍在最近邻搜索算法SPTAG的安装及使用 - 知乎 (zhihu.com)。
KNN(最近邻搜索)可参考机器学习(一)——K-近邻(KNN)算法 - 1ang - 博客园 (cnblogs.com),欧几里得距离、曼哈顿距离和切比雪夫距离_tianlan_new_start的博客-CSDN博客_欧几里德距离,新浪博客 (sina.com.cn)
步骤:
计算测试数据与各个训练数据之间的距离; 按照距离的递增关系进行排序; 选取距离最小的K个点; 确定前K个点所在类别的出现频率; 返回前K个点中出现频率最高的类别作为测试数据的预测分类;几类距离:
闵可夫斯基距离:欧式距离:d(x,y)=∑k=1n(xk−yk)2d(x,y)=\sqrt{\sum_{k=1}^n(x_k-y_k)^2} 曼哈顿距离: d(x,y)=∑k=1n|xk−yk|d(x,y)=\sqrt{\sum_{k=1}^n|x_k-y_k|} 切比雪夫距离:本站所有文章、数据、图片均来自互联网,一切版权均归源网站或源作者所有。
如果侵犯了你的权益请来信告知我们删除。邮箱:dacesmiling@qq.com