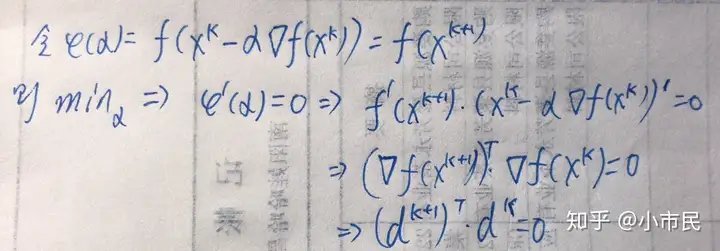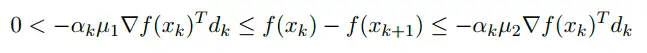相关理论:优化方法、数值分析、矩阵论代码:使用Julia语言,在REPL上测试涉及算法:一阶最速下降法(梯度法)、二阶牛顿法、共轭梯度法、变换轮换法、鲍威尔法单形替换法采用数值分析的理论实现,即采用迭代法,从某一个初始值开始,沿某一方向和长度进行搜索求解使函数值下降,即
4.3、使用梯度方向+全松驰步长的最速下降法
4.3.1、搜索方向的正交性
由上可看出,这种方向相相邻搜索方向相互正交。
4.3.2 程序
使用3.2中的函数对4.3.1中的算法编程(julia语言):
#= program1.jl
使用梯度方向+全松驰算法迭代法求函数 f(x)=x1^2+25x2^2的极小点。
迭代起始点为 x0=[2;2]。
显然已知最小点为(0,0),按前向误差|x*-x|的二范数最小设置终止条件。 =#
using LinearAlgebra, Plots; gr()
# 将 f(x)转换为矩阵形式,也可以不用转,但求梯度方便。
G = [2 0;0 50];
gradient_fx(x) = G * x;
f(x) = 0.5 * x * G * x;
f2(x1, x2) = x1^2 + 25x2^2;
x_next = [2;2];
x_list = copy(x_next);
y_list = [f(x_next)];
grad_list = [0.0;0.0];
alpha_list = [0.0];
TOL = 0.0001;
while norm(x_next) > TOL
global x_next, x_list, y_list, grad_list, alpha_list;
# 计算当前点梯度
gradient_k = gradient_fx(x_next);
# 计算步长
alpha = (x_next * G * gradient_k) / (gradient_k * G * gradient_k);
# 计算下一点
x_next = x_next - alpha * gradient_k;
# 将运算过程中的值保存
x_list = hcat(x_list, x_next);
y_list = push!(y_list, f(x_next));
grad_list = hcat(grad_list, gradient_k);
alpha_list = push!(alpha_list, alpha);
end
data = hcat(hcat(hcat(x_list, y_list), alpha_list), grad_list);
data = @. round(data, digits = 4);
println("k \t x1 \t x2 \t f(x) \t alpha \t Gradient_x1 \t Gradient_x2");
row_len, col_len = size(data);
for row in 1:row_len
print(row, "\t")
for col in 1:col_len
print(data[row, col], "\t");
end
println("");
end
lims_x1 = -3:0.01:3;
lims_x2 = -3:0.01:3;
p = contour(lims_x1, lims_x2, f2, fill = true);
display(p)
png("contour");
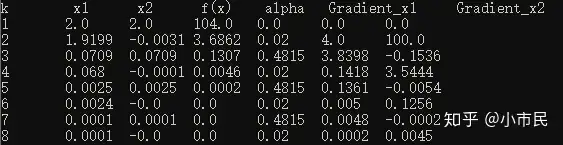
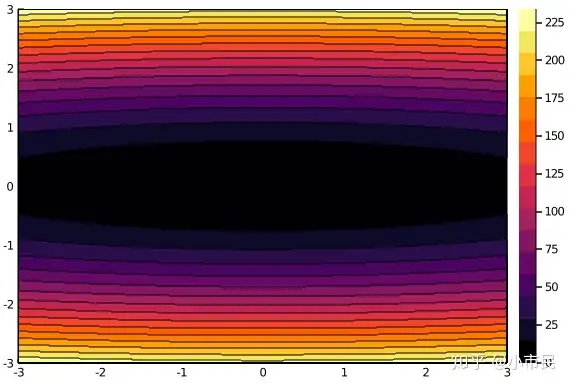
从上图的结果中计算可得出,相邻的梯度向量之间是正交的。
等高线图4.4 使用梯度方向+Armijo-Goldstein准则(以下简写AG准则)
4.4.1 解释
在参考4和5中已经完美的解释了大部分内容,但是编码的时候发现还有有些问题,想了一个晚上加调试发现了端倪,充分证明了实践是检验真理的唯一标准(@-@)。以下是对参考4和5的补充说明。
首先对参考4进行修正说明,
注意:上图中默认了搜索方向 dkdk 与负梯度方向 −gk- gk的夹角是锐角,因为只有这样才能满足函数值下降。参考4中只解释了将式(1)泰勒级数展开满足要求,但却没有说将(2)式展开泰勒展开。如果按上图上把两式都一阶泰勒展开,因为 0">α>0\alpha > 0,显然(1)式永远符合要求,(2)式不符合要求,产生了悖论AG原则多写了式(1),而且式(2)永远不能满足。出现问题,还是先从自身的解释找原因比较好。
Q:只要搜索方向与负梯度方向成锐角,函数值就下降?
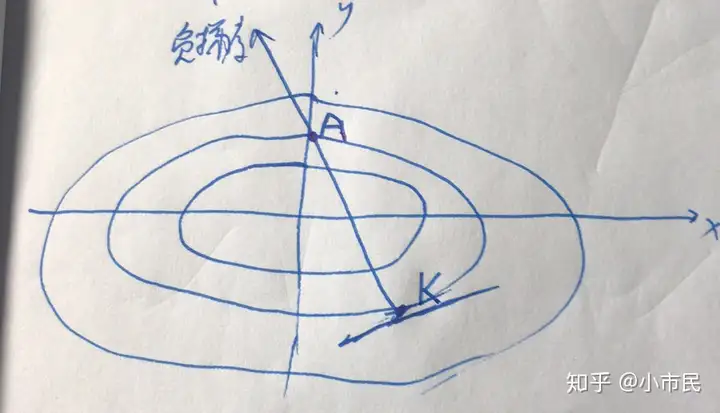
A:这句话要加上一个限定条件,在当前点的某个小范围内。因为只有在这个小的范围内,才能满足泰勒展开的条件,推导出函数值下降。从另一个角度考虑,也可以说只有在上述搜索方向上的小范围内的步长才能满足函数值下降。
如上图所示,假设取搜索方向为负梯度方向,显示当搜索步长在KA两点之间的时候才能满足函数值下降,否则函数值就会上升,因此AG准则中要求了函数值必须下降的要求。参考5中的公式:
解释的相对比较清楚,明确了函数值的下降,也说明了不能用一阶泰勒展开解释,因为如果用一阶泰勒展开,上式可等价于:μ1αk≤αk≤μ2αk\mu_1 \alpha_k \leq \alpha_k \leq \mu_2 \alpha_k 显然中间不能成立。下面先给出程序及结果,然后继续解释。
4.4.2 程序
#= program2.jl使用梯度方向+Goldstein-Armijo准则求函数 f(x)=x1^2+25x2^2的极小点。
迭代起始点为 x0=[2;2],Armijo准则参数 u1=0.2, u2=0.8, p1=0.5, p2=1.5。显然已知最小点为(0,0),按前向误差|x*-x|的二范数最小设置终止条件,
也可按照|x[k+1]-x[k]|< TOL来设定终止准则。 =#
using LinearAlgebra
# 将 f(x)转换为矩阵形式,也可以不用转,但求梯度方便。
G = [2 0;0 50];
gradient_fx(x) = G * x;
f(x) = 0.5 * x * G * x;
x_next = [2;2];
x_list = copy(x_next);
y_list = [f(x_next)];
grad_list = [0.0;0.0];
alpha_list = [0.0];
# 设置Armijo准则参数
u1 = 0.2;
u2 = 0.8;
p1 = 0.5;
p2 = 1.5;
TOL = 0.0001;
while norm(x_next) > TOL
global x_next, x_list, y_list, grad_list, alpha_list;
# 计算当前点梯度
G_k = gradient_fx(x_next);
y_k = f(x_next);
# 设置搜索方向
dk = -G_k;
# 计算步长
alpha = 1.;
# 设置一个布尔量控制循环跳出
gate_alpha = true;
while gate_alpha
if (-alpha * u1 * G_k * dk) > (y_k - f(x_next + alpha * dk))
alpha = p1 * alpha;
continue;
end
if (y_k - f(x_next + alpha * dk)) > (-alpha * u2 * G_k * dk)
alpha = p2 * alpha;
continue;
else
gate_alpha=false;
end
end
# 计算下一点
x_next = x_next - alpha * G_k;
# 将运算过程中的值保存
x_list = hcat(x_list, x_next);
y_list = push!(y_list, f(x_next));
grad_list = hcat(grad_list, G_k);
alpha_list = push!(alpha_list, alpha);
end
data = hcat(hcat(hcat(x_list, y_list), alpha_list), grad_list);
data = @. round(data, digits = 4);
println("k \t x1 \t x2 \t f(x) \t alpha \t Gradient_x1 \t Gradient_x2");
row_len, col_len = size(data);
for row in 1:row_len
print(row, "\t")
for col in 1:col_len
print(data[row, col], "\t");
end
println("");
end
结果一部分结果:
4.4.3 解释一阶泰勒的问题
首先使用下列代码绘制图形:
#= image_of_f.jl
绘制等高线图解释Armijo-Goldstein准则,函数f(x,y)=x^2+25y^2 =#
using LinearAlgebra, Plots;gr()
f(x,y) = x^2 + 25y^2
f1(x, z) = sqrt(z - x^2) / 5;
f2(x, z) = -sqrt(z - x^2) / 5;
# 绘制(2,2)点处的等高线
z = f(2, 2);
x = -3:0.001:3;
plot(x, hcat(f1.(x, z), f2.(x, z)),c = [:blue :blue],legend = false, framestyle = :zerolines)
# 绘制(2,2)到下一迭代点(1.875, -1.125)的长度
plot!([2;1.875], [2;-1.125], c = [:red], marker = :dot, arrow = 2)
# 绘制(1.875, -1.125)处的等高线
z = f(1.875, -1.125);
plot!(x, hcat(f1.(x, z), f2.(x, z)),c = [:yellow :yellow],legend = false, framestyle = :zerolines)
# 绘制函数值下降最多处(1.9199, -0.0031)点的等高线
z = f(1.9199, -0.0031);
x_max = floor(sqrt(z), digits = 6);
x2 = -x_max:0.01:x_max;
plot!(x2, hcat(f1.(x2, z), f2.(x2, z)),c = [:black :black],legend = false, framestyle = :zerolines)
# 绘制第二个点的一阶泰勒展开的等高线
alpha = 0.0312;
z = f(1.875, -1.125) - alpha * dot([4;100], [4;100]);
gui()
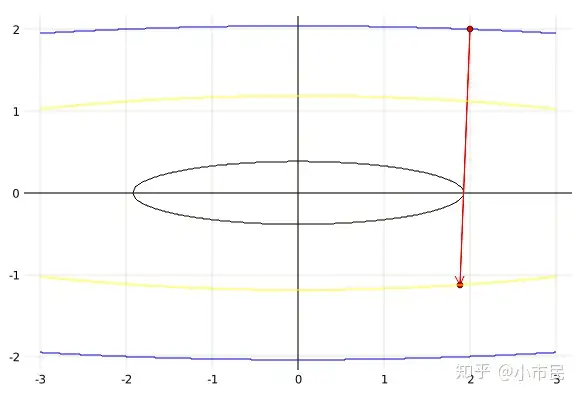
上面的程序和结果是针对初始点和下一点之间的几何关系图像,然后将函数在第二点处二阶泰勒展开: f(xk+1)=f(xk−αdk)≈f(xk)−α▽Tf(xk)dk+12α2dkTGdkf(x_{k+1})=f(x_k - \alpha d_k) \approx f(x_k) - \alpha \triangledown^T f(x_k) d_k+\frac{1}{2}\alpha^2 d_k^TGd_k ,取 dk=▽f(xk)d_k = \triangledown f(x_k) ,代入第1点和第2点数据得: f(1.875,−1.125)=f(2,2)−0.0312∗[4,100]∗[4;100]+0.5∗0.03122∗[4,100]∗[2,0;0,50]∗[4;100]⇓35.1562≈104−312.4992+243.376f(1.875, -1.125) = \\ f(2,2) - 0.0312*[4,100]*[4;100] +0.5*0.0312^2*[4,100]*[2,0;0,50]*[4;100]\\ \Downarrow \\ 35.1562 \approx 104 -312.4992+243.376
这里就很完美的解释了4.4.1中的悖论,即使用一阶泰勒近似时结论有问题。从上面的数据可以看出问题出在一阶泰勒的误差是非常大的,也说明了αdk\alpha d_k 的值不足以小到可以使用一阶泰勒近似。
4.4.4 解释收敛性
通过AG和全松驰的收敛性比较,可以看出本例中AG的收敛速度是比全松驰慢的,猜测这个可能跟终止准则的设置不合理有关。
4.5 牛顿法及其变种
4.5.1 理论推导
牛顿 法:在 xkx_k 处将 f(x)f(x) 二阶泰勒展开, 如下所示:f(x)≈f(xk)+▽Tf(x−xk)(x−xk)+12(x−xk)TH(x−xk)f(x) \approx f(x_k) + \triangledown^Tf(x-x_k)(x-x_k)+\frac{1}{2}(x-x_k)^T H (x-x_k)
然后将上式对 xx 求导并取0,得到下一个近似的极小值点 xk+1x_{k+1} 。
,即为f′(x)=0⇒▽f(xk)+H(x−xk)=0⇒x=xk−H−1▽f(xk),x即为xk+1f(x)=0 \Rightarrow \\ \triangledown f(x_k) + H(x-x_k) =0 \Rightarrow \\ x=x_k - H^{-1} \triangledown f(x_k),x即为x_{k+1}
注意:上式也可以理解为搜索方向dk=−H−1▽f(xk)d_k=-H^{-1} \triangledown f(x_k) 步长 αk=1\alpha_k=1的搜索,但是上式并不未包含沿下降方向搜索的含义,只是求了个极值点。除此之外,搜索方向还需要计算二阶海森矩阵的逆,可能无法实现。
阻尼牛顿法:定义 dk=−H−1▽f(xk)d_k=-H^{-1} \triangledown f(x_k)为牛顿方向,也是此算法的搜索方向,改变的是步长,定义阻尼因子αk\alpha_k 为沿牛顿方向一维搜索的最佳步长,即:f(xk+1)=f(xk+αkdk)=minαf(xk+αdk)f(x_{k+1})=f(x_k+\alpha_k d_k)=min_\alpha f(x_k+\alpha d_k)
拟牛顿法:针对牛顿法中需要计算二阶海森矩阵及其逆的问题,使用一个对称正定的矩阵来代替H进行计算,并在计算中更新此近似矩阵。4.5.2 程序(阻尼牛顿法)
#= program3.jl
使用阻尼牛顿法求函数 f(x)=x1^2+25x2^2的极小点。 =#
using LinearAlgebra;
# 将 f(x)转换为矩阵形式,也可以不用转,但求梯度方便。
G = [2 0;0 50];
gradient_fx(x) = G * x;
f(x) = 0.5 * x * G * x;
f2(x1, x2) = x1^2 + 25x2^2;
x_next = [2;2];
x_list = copy(x_next);
y_list = [f(x_next)];
grad_list = [0.0;0.0];
alpha_list = [0.0];
TOL = 0.0001;
while norm(x_next) > TOL
global x_next, x_list, y_list, grad_list, alpha_list;
# 计算当前点梯度
gradient_k = gradient_fx(x_next);
# 设置搜索方向为牛顿方向
d_k = -inv(G) * gradient_k;
# 计算步长为最佳步长
alpha = (x_next * G * [1;1]) / (gradient_k * [1;1]);
# 计算下一点
x_next = x_next + alpha * d_k;
# 将运算过程中的值保存
x_list = hcat(x_list, x_next);
y_list = push!(y_list, f(x_next));
grad_list = hcat(grad_list, gradient_k);
alpha_list = push!(alpha_list, alpha);
end
data = hcat(hcat(hcat(x_list, y_list), alpha_list), grad_list);
data = @. round(data, digits = 4);
println("k \t x1 \t x2 \t f(x) \t alpha \t Gradient_x1 \t Gradient_x2");
row_len, col_len = size(data);
for row in 1:row_len
print(row, "\t")
for col in 1:col_len
print(data[row, col], "\t");
end
println("");
end

从结果上看,阻尼牛顿法是真的666,精确搜索,一步到位。从结果中也能看出这个例子比较特别,正好阻尼牛顿和牛顿法是一致的。猜测应该是对于二次函数,这两种方法是一致的。
4.5.3 拟牛顿法(使用变尺度矩阵实现)
尺度矩阵-以二次型函数为例使用 x \leftarrow Qx 代入标准二次型函数中,二次项变为: \frac{1}{2}x^TGx \leftarrow \frac{1}{2}x^TQ^TGQx,目的是改变二次项的偏心程度,使函数偏心率减小,函数的等值面变为球面,这样任意点的梯度都指定球心(即最小点)。通俗的说,将一个椭圆形的等高线转变为同心圆,这样每点的负梯度方向指定球心。
若G是对称正定矩阵,则通过LDLt分解(或相似对角化或相似正交对角化)可使 Q^T GQ =I ,这样变换后的二次项为单位矩阵,即偏心率为0.再对上式进行变换可得: Q^TG=Q^{-1} \Rightarrow QQ^TG=I \Rightarrow H=QQ^T=G^{-1} ,这样可能通过Q求G的逆矩阵。当用H来代替代替牛顿法中的二阶海森矩阵的逆里,即为拟牛顿法的一种实现方法。
变尺度矩阵的建立-对于一般函数采用牛顿法,更新方程为 x_{k+1} = x_k -\alpha_k G_k^{-1} \triangledown f(x_k) ,其中 \alpha_k采用一维搜索的最佳步长(即函数值下降最大)。
构造一个矩阵序列 \{ H_k \} 来逼近海森矩阵的逆序列 \{ G^{-1} \} ,每迭代一次,尺度矩阵就改变一次,称之为变尺度。为了使 H_k满足近似且容易计算,需要加上以下附加条件:
\{ H_k \} 中每一个元素都是对称正定,这样才能满足搜索方向 d_k=-H_k \triangledown f(x_k) 为下降方向迭代简单。一个简单的校正公式为 H_{k+1} = H_K +E_k ,其中 E_k 为校正矩阵\{ H_k \} 满足拟牛顿条件。直接给结论, H_{k+1}(g_{k+1}-g_k) = x_{k+1} - x_k \\ \Downarrow \\ y_k=(g_{k+1}-g_k) \quad s_k=x_{k+1} - x_k \\ \Downarrow \\ H_{k+1} y_k = s_k ,其 中 g_k表示第 k 次迭代处的梯度。推导方法跟共轭方向法有相通的地方,对于二次函数,能产生对G共轭的搜索方向,也可以看作一种共轭方向法。条件2和3看似是冲突的,因为在每次的迭代中 y_k, s_k 是可能求出的,然后仅按照这两个向量是无法辨识出唯一的 H_{k+1},所以需要使用条件2 进行迭代。
条件2的实现需要 E_k 的确定, (H_k +E_k)y_k = s_k \Rightarrow E_k y_k = s_k -H_k y_k 即是 E_k需要满足的条件。按照这一条件构造不同的E_k ,就形成了不同的变尺度法,DFP就是其中的一种。直接给出DFP的校正公式如下:
H_{k+1} = H_k + \frac{s_k s_k^T}{s_k^T y_k} - \frac{H_k y_k y_k^T H_k}{y_k^T H_k y_k}, k=0, 1, 2, ...
4.5.4 程序框图及代码-变尺度法
变尺度法的程序框图程序(使用DFP的变尺度法):
#= program4.jl使用拟牛顿法(基于DFP的变尺度法)求函数 f(X)=0.5*X^T*G*X+b^TX的极小点,
其中G=[2 -2; -2 4], b=[-4;0]。 =#
using LinearAlgebra, Plots; pyplot()
# 定义函数
G=[2 -2; -2 4];
b=[-4;0];
f(X) = 0.5 * X * G * X + b * X;
f2(x1, x2) = x1^2 + 2x2^2 - 4x1 - 2x1*x2;
# 求梯度
g_fx(X) = G * X + b;
# 设置初始参数
x_k = [1.0;1];
H_k = [1.0 0; 0 1.0];
# 设置误差
TOL = 0.0001;
# 设置最大循环次数
N_MAX = 30;
# 设置布尔量控制循环
gate = true
# 设置数组来保存运算过程中的结果
x_list = [];
y_list = [];
g_list = [];
alpha_list = [];
H_list = [];
while gate
global x_k, H_k, x_list, y_list, g_list, alpha_list, H_list, gate
# 保存当前的 x 向量
push!(x_list, x_k);
# 保存当前的 y 函数值
push!(y_list, f(x_k));
# 计算当前点梯度
g_k = g_fx(x_k);
push!(g_list, g_k);
# 如果梯度为0,则退出
if norm(g_k)<TOL
gate = false;
end
# 设置变尺度矩阵来近似海森矩阵的逆
if length(H_list)>0
y_k = g_k - g_list[end-1];
s_k = x_k - x_list[end-1];
# 通过DFP算法求Ek
E_k = (s_k*s_k)/(s_k*y_k)-(H_k*y_k*y_k*H_k)/(y_k*H_k*y_k);
# 更新Hk
H_k = H_k + E_k;
push!(H_list, H_k);
else
push!(H_list, H_k);
end
# 设置搜索方向
d_k = -H_k * g_k;
# 计算步长为最佳步长
alpha = -(d_k*(G*x_k+b))/(d_k*G*d_k);
push!(alpha_list, alpha);
# 计算下一点
x_k = x_k + alpha * d_k;
# 判断是否达到精度要求
if norm(x_k-x_list[end]) < TOL || length(x_list) > N_MAX
gate=false;
end
end
# 将数据整合在一起
row_len = length(x_list);
col_len = sum(map(length, [x_list[1], g_list[1], H_list[1]]))+2;
data = zeros(Float64, (row_len, col_len));
for i in 1:length(x_list)
row_x, row_g, row_H = map(vec, [x_list[i], g_list[i], H_list[i]]);
row = hcat(hcat(hcat(hcat(row_x, y_list[i]), alpha_list[i]), row_g), row_H);
data[i, :]=row;
end
# 为了显示美观,将数据保留4位小数
data = @. round(data, digits = 4);
println("k \t x1 \t x2 \t f(x) \t alpha \t Gradient_x1 \t Gradient_x2 \tH-Matrix(2x2)");
for row in 1:row_len
print(row, "\t")
for col in 1:col_len
print(data[row, col], "\t");
end
println("");
end
lims_x1 = -10:0.01:10;
lims_x2 = -10:0.01:10;
p = contour(lims_x1, lims_x2, f2, fill = true);
display(p)
png("contour");
结果:
原函数的等高线图五、无约束优化-共轭梯度法
5.1、共轭方向法原理(不是共轭梯度)
以二次函数 f(x)=\frac{1}{2}x^TGx+b^Tx+c 为例。从初始点 x_0,沿搜索方向d_0 行走步长 \alpha_0 到达 x_1 点,其中 \alpha_0 是此方向上的最佳步长,即在 x_1 点处的负梯度方向与 d_0 垂直,如下图所示:
负梯度方向与共轭方向如上图所示,在选择 d_1
方向时选择一种比较贪婪的方法,希望直接指定最优点
x_* ,那么该怎么确定 d_1 ? 最优点 x_* 处的的导数为0(也等价于梯度为0),所以: \triangledown f(x_*) = Gx_* + b = 0 \Rightarrow \\ \triangledown f(x_1+\alpha_1 d^1) = G(x_1+\alpha_1 d^1) +b \Rightarrow \\ (Gx_1+b) + \alpha_1Gd_1 = \triangledown f(x_1)+ \alpha_1Gd_1=0 \Rightarrow \\ d_0^T \triangledown f(x_1) + \alpha_1 d_0^TGd_1=0 \Rightarrow \\ \alpha_1 d_0^TGd_1=0
注意: d_0^T \triangledown f(x_1)=0 是由上步中搜索步长最佳得到的, \alpha_1 不能为0,否则当前点即为最优点。因此由最后一个等式可得:当相邻两个搜索方向关于G共轭的时候,那么每步的搜索方向均指向最优点。称这样的向量为关于G共轭或共轭方向。当G是单位矩阵归,共轭退化为正交。
共轭向量组有一些性质:
非m个非零向量对一个对称正定矩阵G共轭,则这m个向量是线性无关的。反之,可推导出若m个向量线性相关,则必不相对于G共轭。线性无关是一个必要条件。在n维空间中互相共轭的非零向量的个数不超过n。从任意初始点出发,顺次沿n个G的共轭方向进行一维搜索,最多经过n次迭代就可以找到二次函数的极小点。注:共轭方向与牛顿方向推导区别,牛顿方向是在迭代点附近二阶泰勒展开求导找最优值,共轭方向是整个函数求导寻最优解。
5.2、共轭方向的构造
由上述可知,算法的难点在于共轭向量组的构建。对应于不同的构造方法,形成不同的共轭方向法,如共轭梯度法,鲍威尔法等。施密特正交法的推广也可以从n个线性无关的得到共轭向量组。由于篇幅,不再细述,参考6中有解释。
5.3、共轭梯度法
共轭梯度法是共轭方向法中的一种,因为每一个共轭向量依赖于迭代点处的负梯度而构造出来。推导如下:还以上文中提到的二次函数为例
x_{k+1}-x_k=\alpha_k d_k \Rightarrow\\ g_k = Gx^k+b, \quad g_{k+1} = Gx^{k+1}+b \Rightarrow \\ g_{k+1}-g_k=G(x_{k+1}-x_k)=\alpha_kGd_k
若已知某一方向向量 d_j^TGd_k=0 ,即成共轭方向,则: d_j^T(g_{k+1}-g_k)=0 ,说明 d_k的一个共轭方向与相邻点的梯度差正交,不用计算G即可算出共轭方向。
共轭梯度法的几何说明由于推导复杂,直接给出结论:共轭方向的递推公式为:
其中, g_k 是第 k 步的梯度。
5.4、共轭梯度法程序框图
5.5、程序(共轭梯度法)
#= program5.jl
使用共轭梯度法求函数 f(X)=0.5*X^T*G*X+b^TX的极小点,
其中G=[2 -2; -2 4], b=[-4;0]。 =#
using LinearAlgebra;
# 定义函数
G = [2 -2; -2 4];
b = [-4;0];
f(X) = 0.5 * X * G * X + b * X;
# 求梯度
g_fx(X) = G * X + b;
# 设置初始参数
x_k = [1.0;1];
# 设置误差
TOL = 0.0001;
# 设置最大循环次数
N_MAX = 30;
# 设置布尔量控制循环
gate = true
# 设置数组来保存运算过程中的结果
x_list = [];
y_list = [];
g_list = [];
alpha_list = [];
conj_list = [];
while gate
global x_k, conj_k, x_list, y_list, g_list, alpha_list, conj_list, gate
# 保存当前的 x 向量
push!(x_list, x_k);
# 保存当前的 y 函数值
push!(y_list, f(x_k));
# 计算当前点梯度
g_k = g_fx(x_k);
push!(g_list, g_k);
# 如果梯度为0,则退出
if norm(g_k) < TOL
gate = false;
end
# 求共轭方向
if length(conj_list) > 0
beta_k = norm(g_k)^2 / norm(g_list[end - 1])^2;
conj_k = -g_k + beta_k * conj_k;
push!(conj_list, conj_k);
else
conj_k = -g_k;
push!(conj_list, conj_k);
end
# 设置搜索方向
d_k = conj_k;
# 计算步长为最佳步长
alpha = -(d_k * (G * x_k + b)) / (d_k * G * d_k);
push!(alpha_list, alpha);
# 计算下一点
x_k = x_k + alpha * d_k;
# 判断是否达到精度要求
if norm(x_k - x_list[end]) < TOL || length(x_list) > N_MAX
gate = false;
end
end
# 将数据整合在一起
row_len = length(x_list);
col_len = sum(map(length, [x_list[1], g_list[1], conj_list[1]])) + 2;
data = zeros(Float64, (row_len, col_len));
for i in 1:length(x_list)
row_x, row_g, row_H = map(vec, [x_list[i], g_list[i], conj_list[i]]);
row = hcat(hcat(hcat(hcat(row_x, y_list[i]), alpha_list[i]), row_g), row_H);
data[i, :] = row;
end
# 为了显示美观,将数据保留4位小数
data = @. round(data, digits = 4);
println("k \t x1 \t x2 \t f(x) \t alpha \t Gradient_x1 \t Gradient_x2 \t Conj-Vector(2)");
for row in 1:row_len
print(row, "\t")
for col in 1:col_len
print(data[row, col], "\t");
end
println("");
end
结果 :
六、坐标轮换法及鲍威尔方法
6.1、坐标轮换法
每次搜索只允许一个变量变化,其余变量保持不变,即沿坐标方向轮流进行一维搜索最佳步长的寻优方法。把多变量的优化问题轮流地转化为单变量的优化问题。计算过程中不需要目标函数的导数,相对简单。缺点是要经过多次曲折迂回的路径才能达到极值点,尤其在极值点附近步长很小,收敛很慢。
坐标轮换法的搜索过程6.2、鲍威尔方法
基本思想是在不用导数的前提下,直接利用函数值来迭代构造共轭方向的一种共轭方向法
6.2.1 共轭方向的产生
通过一维方向确定共轭方向上图中, x_k 和 x_{k+1} 为从不同点出发,沿同一方向 d^j (平行向量也是同一方向)进行一维搜索最佳步长得到的点,显然由之前的推导可得: (d^j)^Tg_k = (d^j)^Tg_{k+1}=0 ,又两点的梯度表示为: g_k = Gx_k+b \quad g_{k+1}=Gx_{k+1}+b \Rightarrow g_{k+1}-g_k = G(x_{k+1}-x_k),因此有:(d^j)^T(g_{k+1}-g_k)=(d^j)^TGd_k=0,\quad d^k=x_{k+1}-x_k ,说明 d^j和d^k 关于G共轭。
6.2.2 鲍威尔算法
二维鲍威尔法的几何表示按照坐标轮换的思路,首先选择各坐标轴上的单位向量轮流搜索最佳步长得到x_2^0 点,然后使用起始点 x^0 与此点的连续方向取代第一个坐标方向 d_1 组成新的线性无关向量组(即 e_2, d^1)作为下一轮的搜索方向得到点x_1^1和x_2^1 ,由6.2.1中的结论可知 x_0^1和x_2^1 的连线方向 d^2 与 d^1 是共轭方向,然后进行新的搜索。
6.2.3 改进鲍威尔
由于鲍威尔算法中的新生成的向量组可能会线性相关,因上,在改进算法中需要判断向量组中的哪个向量最坏,然后用新产生的向量替换这个最换的向量,以保证逐次生成共轭方向。具体不再细述。
七、单形替换法
上述的方法都使用了函数的导数,在不计算导数的情况下,先算法若干个点的函数值,从它们的大小关系中看出函数的变化趋势,寻找下降方向,这就是单形替换法的思路。
单纯形指的是n维空间中具有n+1个顶点的多面体。利用单纯形的顶点,将函数值进行大小排序,从而确定有利的搜索方向和步长,找到一个好的点替换单纯形中较差的点,使单纯形不断地向目标函数的极小值靠近,直到搜索到极小点为止,这就是单形替换法的基本思路。
单形替换法八、总结本文中约束优化方法搜索方向的关系
无约束优化方法搜索方向之间的相互联系后记:
最后的鲍威法和单形变换法没写太多,一方面是因为要转向约束优化的内容,另一方面是貌似知乎出了一个bug,文章图片太多了浏览器总崩溃。
上述优化方法各有各的优点和缺点,应该是针对不同的问题使用不同的方法(这个中国人都知道@-@),具体来说,比如当高维优化中目标函数的二维海森矩阵可不是好求的,更不用说其逆的运算,因此牛顿法就不是很适用了。当一阶梯度求解起来麻烦或难以求解时,就要使用零阶方法了。综合来讲,觉得共轭梯度法比较好些。这些都是搜索方向的选择。对于步长来说,看起来用全松驰(即最佳步长)的求解比较好,应该共轭方向的推导过程中严重依赖最佳步长时的梯度与搜索方向垂直这个条件,Armijio-Goldstein应该也有自己擅长的地方。欢迎读者在这个地方展开激烈讨论。
除此之外,还有一个比较大的问题就是,上述算法求解的都是局部最优解,如何保证局部最佳是全局最优,这就需要凸优化上场了。
特此声明:我在知乎上的所有文章、言论、见解等只代表我个人的观念,与任何研究机构、商业公司等无关。所有文章仅供个人学习交流之用,侧耳倾听任何与文章相关的评论。在文章开头会注明相关引用内容,所引用内容版权归原作者所有,在此一并表示感谢。若未注明之处,由此可能造成的侵权影响请联系本人进行删除或者修改。若个别读者不遵守此声明进行转载,并因此产生商业行为,并造成对文章内引用内容的侵权行为与本人无关。如果文章能对个人学习、工作带来一些思路,那么文章的目的已经达到。如果引用文章相关内容,请注明出处。