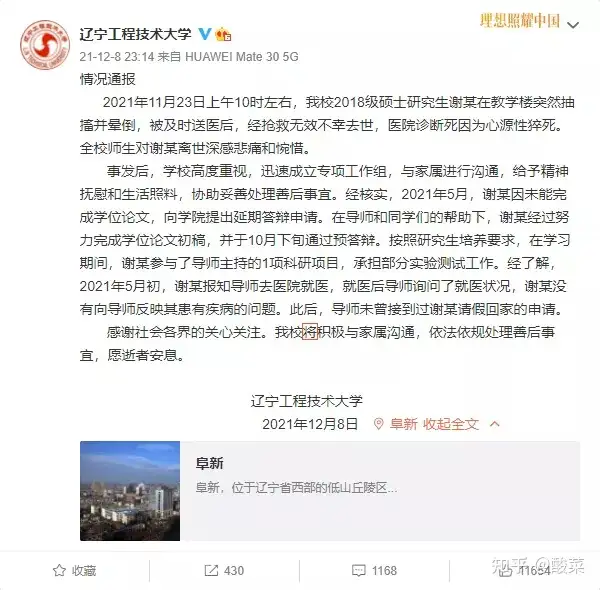
906软件基础数据结构部分
906软件部分是分为c++ 和 数据结构的 ,c++ 部分已有专门的文章进行书写,数据结构部分有两篇文章是写图论的,数据结构考点很多,如果将每个考点都用单独的文章来写的话,就显的很零碎,于是我就在本文对数据结构进行统一的整理和描述。
下面的试题是2019年906真题 , 该文章会继续记录最近几年906考试的题目。
B树和B+树的优缺点:
B树是所有节点的平衡因子是0的多路平衡查找树。磁盘算法是基于B树来实现的,数据库存储使用的是B+树,B树的查找方式是节点存储在硬盘中,找到该节点之后在找关键字,这时候将该节点读入内存,从内存中找到该关键字,这是B树的查找过程。B树的插入算法需要对节点进行分裂处理,超过定义的节点数的范围之后,需要按照分裂流程对节点进行分裂处理。同理B树的删除操作涉及到合并问题,也需要实现向上合并的操作,直到所有的节点满足要求。B+树在形式上不同于B树的点是节点中含有的关键节点的范围是([m/2],m),非叶节点中的关键值是每一个子节点的最大值,即是说叶子节点中含有非叶节点的值,这样的安排是为了迎合应用数据库的需求,至于为什么这样写,自己需要查看数据库原理数据,并手动实现一个简单的数据库客户端。
m的确定依据是按照树中所有节点的孩子个数的最大值进行判断的,若B树中含有孩子的个数的最大值是m个 , 那么m就是所求。B+树相对于B树的优点是非叶节点含有的是索引信息,这样就减少了磁盘的IO操作,B+树的查询操作效率相当。
关于m的确定问题 : 一棵m阶B树 , 或为空树 , 或为满足如下特性的m叉树:
1.每个节点至多有m棵子树 , 即至多含有m-1个关键字;
2.除了叶节点之外所有非叶节点至少含有[m/2]棵子树 , 即至少含有[m/2]-1 棵关键字;
照2的说法 , 树含有的最大分支数就是m ,找m 肯定得从叶节点的上一级找;
B+树:每一个分支节点最多有m棵子树 ; B+树的查找过程 , 都是从根节点到叶节点的路径;
给出先序中序,求出二叉树:
思路: 先序遍历的第一个节点是根节点,在中序遍历中定位到根节点的位置,根节点的左侧就是左子树,根节点的右侧就是右子树 , 采用的方式是使用递归的方式对数组进行遍历,生成左子树和右子树。
单链表中给一指针指向M ,如何删除M,如何在M中添加节点:
删除M的方式是从头节点遍历到M , 之后对M进行删除操作。通过使用next指针的方式进行操作。在M前插入新的节点,通过prev指针实现。M->prev = M->prev->prev;
一个无向图节点的度都大于等于2,问是否有回路存在:
节点的度都大于2,显然是有回路存在。边的数量是n , 节点的数量是n , 说明是有环存在的。
输入栈顺序固定,中途可以随意出栈,可以输出任何序列嘛:
是不可以的,举例说: 1 2 3 4 是输入栈顺序,序列1 2 4 3是无法得到的。
求叶子节点数目:
编程: 使用中序遍历树,设置一个计数变量,如果节点是没有左右孩子的情况下,计数变量加加,最后计数变量的值就是叶子节点的数量。
给出有向图的出度表,如何得到各节点的入度表:
也是遍历邻接表,通过遍历出度的方式,可以得到入读表;
双环链表的指针P指向W,叙述快速找到尾节点的方法: (疑问:双环链表这里有尾节点嘛?) 看了王道的数据结构图书 , 双环链表的头节点指向尾节点。 快速找到尾节点的方式双向同时遍历,这样快速找到。
中缀序列转换为后缀序列:
试卷上的中缀序列转换为后缀序列: 注意中缀序列转换为后缀序列的规则 , 栈内的元素总是大于栈外,对于中缀表达式,碰到变量直接输出,碰到运算符,将其与栈顶的元素符号进行比较,低的情况弹出,等于或高于的情况压入栈中,等于弹出栈顶符号不需要输出,最终得到的是后缀表达式;
a+b-c/(e-f) 转换为后缀表达式是:
ab+/cef--;
反一下: 后缀表达式转换为中缀表达式是:
后缀表达式的转换过程可以只使用一个栈来实现,举例说:
ABCD-*+EF/-;
转换结果是:A+B*(C-D)-(E/F); // 好简单。。
描述题目:双散列算法处理冲突的原理:
双散列,也就是再散列 , 第一次散列出现冲突,第二次使用散列函数(不同于第一次) , 对数列进行第二次散列,使用这样的方式来处理冲突。双散列函数的数学表达式是:
Hi=(H(key)+i∗Hash2(key))/mH_{i} = (H(key) + i * Hash_{2}(key)) / m;//实际上是取余 , %符号latex 不会用 , 有读者可指出正确的使用latex 写出取余符号的方法;
再散列的方式其实属于开放定址的方式 , 开放定址法的含义是可存放新表项的空闲地址既像它的同义词表项开放,也向它的非同义词表项开放。数学递推公式为:
Hi=(H(key)+di)/m;H_{i} = (H(key) + d_{i}) / m; //同样的,取余符号不会用latex 来实现。。。
开放定址法的族有以下成员:
线性探测法 , 平方探测法 , 再散列法 , 伪随机数法;
除了开放定址法之外,还可以使用拉链法,拉链法其实就是开辟新的存储空间,如果散列函数返回相同的结果的话。
散列表还会考到求平均查找长度 , 平均成功查找长度, 平均失败查找长度 , 装载效率alpha;
王道关于散列函数的一道题是: 1) 求出散列函数表达式, 2) 等概率情况下查找成功,查找失败的平均查找长度;
散列函数的表达式是h(key) % p ; //题设给出;
题设给出的装填因子alpha , 那么 根据关键字的数量可以求出散列表的长度 , p值是小于散列表长度的最大素数 , 进而得到p ,求出散列函数的表达式;
第二问是在拉链法的基础上进行计算的, 拉链表计算平均失败查找长度的方法是: 只要在某一个地址下面有数据 ,数据的个数就是失败的次数 , 求和 , 除以 表的长度就是最终的结果;
排序问题:
快速排序和堆排序稳定吗:
->> :快速排序不稳定 , 堆排序不稳定;
=======================2020.11.2 分析:
无向连通图中,求最大连通子图 , 并用伪代码写出结果:
1) : 叙述算法思想: 使用并查集来求最大连通子图 ,
最大连通子图:
2) : 获取哈夫曼编码的过程:
首先应该想到的是针对某一个节点获取哈夫曼编码 , 所以函数的参数是节点Node* data ;
然后通过遍历其左右孩子 ,有的话 , 用栈记录1 ,没有的话 , 用栈记录0 ,最后到根节点的时候,弹出栈,就是该节点的哈夫曼编码;
2019 年的试题中出现了求类模板的试题:
类模板的基本写法是:=======================2020.11.8 :
今天起的比较晚 , 太累了 , 起不来, 上午8点才起床。计划上午复习一下数据结构和c++的知识 ,下午复盘一下数学二 , 英语政治利用小段时间复习;
2018 年试卷中出现了KMP算法 ,手动求next(j) , 该题的解法是:
next [j] 的计算公式:
next: max{k , 1 < k < j } 且 p1....pk = pj-k+1...pj-1;
prim 算法 和 kruskal 算法求最小生成树的步骤 , 题目是给出图 , 求出两个算法每一步的步骤:
prim算法是 首先从一个节点 开始 , 找和这个节点距离最小的节点,连接 , 之后在从连接的这个点继续寻找节点 , 直到边数是节点数减一的结果;
kruskal 算法是 选择权值小的边进行连接, 直到所有的节点都连接上;
通过王道课本上的例题看出 , 最小生成树的结果是唯一的 , 在不存在权值相等的前提下;
给出散列表 ,求出成功和失败的平均查找次数; 这一道题在王道数据结构单科书中有, 下面对其进行简单的记录 , 另外在计算平均成功查找长度个平均失败查找长度时 , 注意是线性探测法还是链地址法,因为两种计算方式是不一样的;
自己再一次做时 , 平均查找失败的计算是错误的 , 原因是 对于查找失败的理解不正确,我的理解是 : 比如说 查找元素0 , 她的位置是在0 的位置 , 查找失败的次数是10 , 因为列表长度是11 , 剩下的10个元素都是查找失败的结果 ; 王道给出的解释是 : 对于计算地址为0 的关键字key0 , 只有探测完0-8之后才能确定该元素不在表中 , 比较次数为9;依次类推 , 对于地址为1 的元素 , 只有计算完1-8 , 之后 ,才可以确定该元素不在表中, 所以比较次数为8 , 最后求和 除以11 就是平均失败 的查找次数 ;
链地址法: 平均成功查找次数 : 是按照层数来的 ,计算每一层的元素数量 , 之后进行求和 , 在除以列表 的元素数量就是平均成功查找长度;
平均失败查找次数 , 在链表中的计算方式 是 , 失败的查找方式是: 每一个链条的含有的元素数量加1 , 就是每一个链条失败的次数 , 最后求和 , 除以11 , 得出来就是平均失败查找次数 ; 有的说法是把空比较的次数不算做查找失败里面 , 也即是说 每一个链条的数量不需要加1 , 王道采用的是第一种算法 , 我也就用第一种算法来计算;
=======================2020.11.29
是真的好久没有来这里了,也是真的好久没有看数据结构了,906 的复习前一段时间的重点是c++ ,所以对于数据结构没有给予充足的时间复习,对于数据结构还是要提上日程,继续对其进行复习总结; 看到群里面东大学长总结了一些关于如何建最大堆的问题,发现建最大堆的过程自己并不是很熟悉,注意点是从右到左,从下到上,这个注意点自己平时也没有注意到,所以发现这一点之后,自己需要加大对数据结构的复习强度;
看数据结构时候发现不知道该怎样进行复习了,看真题吧, 一道一道的看,也没多大意思,我觉得还是得从框架开始,现在自己先画出数据结构的大框图,并继续塞肉,看看自己有哪一些基本的知识点没有掌握,就从这些没有掌握的知识点开始突破,最终实现对数据结构的复习;
首先还是从图开始进行突击,之后在继续进行别的数据结构内容的复习,一块一块的进行,先从王道开始,在结合真题,希望在考试之前把知识点复习完;
图论: Dijkastra算法,属于图的应用的范畴,图的应用包括最小生成树、最短路径、有向无环图、拓扑排序、关键路径;最短路径的算法包括 Dijkastra算法,prim 算法,Dijkastra算法基于贪心策略,prim 算法同样也是给予贪心策略的,prim 算法是加入节点来比较的,也就是说,加入节点之后,路径之和反而小于未加入节点之前的路径和,那么对其进行更新;更新的结果是加入节点后的值;floyd 算法是迭代的过程,对于负数仍然适用,但是不能形成回路,有负数可以,但是不能形成环;floyd 算法的时间复杂度是O(v^3);除了遍历方式之外,还需要知道的知识点是有向无环图,有向无环图常用来解决公共式子的问题,拓扑排序使用的是有向无环图,拓扑排序的步骤首先是从节点中找一个没有前驱的顶点并输出,之后从网中删除该顶点和以他为起点的有向边,最后如果当前网中不存在没有前驱的顶点的话,说明不存在拓扑排序,必然有环(拓扑排序是关于 图中有没有环的算法);
=======================2020.12.1
今天是12.1号了, 距离考试还有24天,佳雨说最后一段时间考的是心态,还真的是这样;在最后的这一段冲刺时间下,准备按照模块总结重点知识,获取收益最高的复习知识点,并结合真题复习;
今天记录图:

之后是散列表的复习,因为散列表的查找极为容易出大题,设计散列函数,并计算平均成功查找长度、平均失败查找长度;

散列表涉及到平均成功查找长度、平均失败查找长度;在计算的时候需要注意区分除数,除以的到底是哪一个,是链表长度还是元素的个数;
===================2020.12.2
今天复习的是串,因为只写文字的话,字数太多,就把图片放上去了,图片也是自己写的字;
串着一部分主要内容是 KMP 算法和 next 数组,

妈的, 又是歪的;也就是自己看了。。。。;
串的匹配主要设计到的是 KMP 算法 和 求next 数组(选择题)常考;本站所有文章、数据、图片均来自互联网,一切版权均归源网站或源作者所有。
如果侵犯了你的权益请来信告知我们删除。邮箱:dacesmiling@qq.com