

python爬虫:起点小说的 书名 作者 简介 爬取:
比较详细,涉及到了:
url简单拼接:用“+”就行了2. url简单去重的方法:转换为集合类型(因为集合的不重复性)再遍历爬取,
3. 对于无用的url用if简单的筛选
时间:2020.11.2
起点小说单个网页(https://www.qidian.com/free)内每本书的 书名 作者 简介 爬取:
import time #导入时间模块,用end_time-start_time来计算整个程序运行的时间
start_time = time.time() #获得起始时间
import requests
from bs4 import BeautifulSoup
def get_one_book(url): #定义的get_ong_book()方法来获取一本书的内容
data0 = requests.get(url) # get()方法请求网页
soup = BeautifulSoup(data0.text, lxml) # 解析网页元素存入soup中
title_list = soup.select(div.book-info > h1 > em)# 查找网页标签,这个用谷歌浏览器右键检查,然后在HTML中右键copy选相应selector就行(其中.代表class ,>代表下一层)
title = title_list[0].text # 用.text()方法把title_list输出为字符串(.content方法输出为字节码)
writer_list = soup.select(a.writer) # 用select()查找writer
writer = writer_list[0].text # 把writer的信息转化为字符串类型
intro_list=soup.select(body > div > div.book-detail-wrap.center990 > div.book-content-wrap.cf > div.left-wrap.fl > div.book-info-detail > div.book-intro)
intro=intro_list[0].text.strip() # strip()方法用于移除空格和换行符
data=title:+title+ writer: +writer+ introduce: +intro+ \n\n#指定输出的格式
return data
url =https://www.qidian.com/free
data0 = requests.get(url)
soup = BeautifulSoup(data0.text, lxml)
file = open("D:\\爬虫文件\\11.1起点\\1st.txt", "w", encoding="utf-8") # 打开一个文件,w是若文件不存在则新建一个文件
hrefs_list=soup.select(a[href])
下面利用 集合set()内的元素不重复性 进行了简单的去重操作
set_link = set()
for href in hrefs_list:
link = href.get(href) # 用get()得到href的内容(即链接) get返回的类型为str
if book.qidian in link: # 因为只想得到每本小说的链接,所以利用小说的链接都有book.qidain来筛选
p_link = "http:"+link # 爬取到的链接的http都没有,这里都加一个http
set_link.add(p_link) # 把所有书的链接用add()都加入到set_link中 {注:set_link.add(p_link)是直接在集合set_link上添加,不能set_link=set_link.add(p_link)}
for url in set_link:
file.write(get_one_book(url)) # 用一个循环来遍历所有书的链接,再用get_one_book()方法获取每本书的内容,最后写入文件
file.close() # 关闭文件
end_time = time.time()
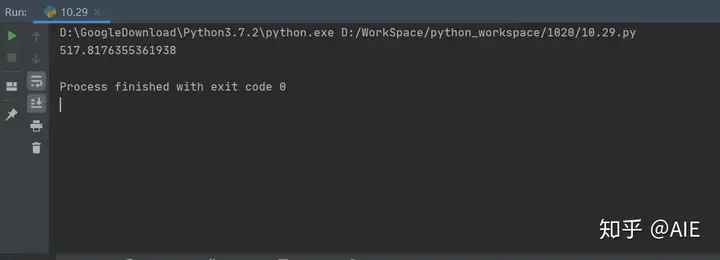
print(end_time-start_time) # 打印运行程序所花时间
居然用了517.8秒
然后写入的文件是这个样子

最后,第一次写编程的文章,python爬虫我也是刚学,有错误请见谅
本站所有文章、数据、图片均来自互联网,一切版权均归源网站或源作者所有。
如果侵犯了你的权益请来信告知我们删除。邮箱:dacesmiling@qq.com


